openEO API (1.3.0)
Download OpenAPI specification:
The openEO API specification for interoperable cloud-based processing of large Earth observation datasets.
Conformance class: https://api.openeo.org/1.3.0
Unless otherwise stated the API works case sensitive.
All names SHOULD be written in snake case, i.e. words are separated with one underscore character (_) and no spaces, with all letters lower-cased. Example: hello_world. This applies particularly to endpoints and JSON property names. HTTP header fields are generally case-insensitive according to RFC 7230 and their respective casing conventions are followed, e.g. Content-Type or OpenEO-Costs, for better readability and consistency.
This specification uses HTTP REST Level 2 for communication between client and back-end server.
Public API implementations MUST be available via HTTPS only.
Endpoints are made use meaningful HTTP verbs (e.g. GET, POST, PUT, PATCH, DELETE) whenever technically possible. If there is a need to transfer big chunks of data for a GET requests to the back-end, POST requests MAY be used as a replacement as they support to send data via request body. Unless otherwise stated, PATCH requests are only defined to work on direct (first level) children of the full JSON object. Therefore, changing a property on a deeper level of the full JSON object always requires sending the whole JSON object defined by the first-level property.
Naming rules of the API endpoints follow the REST principles. Therefore, endpoints are centered around resources. Resource identifiers MUST be named with a noun in plural form except for single actions that can not be modelled with the regular HTTP verbs. Single actions MUST be single endpoints with a single HTTP verb (POST is RECOMMENDED) and no other endpoints beneath it.
The openEO API makes use of HTTP Content Negotiation,
including, but not limited to, the request headers Accept, Accept-Charset and Accept-Language.
JSON
The API uses JSON for request and response bodies whenever feasible. Services use JSON as the default encoding. Other encodings can be requested using HTTP Content Negotiation (Accept header). Clients and servers MUST NOT rely on the order in which properties appear in JSON. To keep the response size small, lists of resources (e.g. the list of batch jobs) usually should not include nested JSON objects, if this information can be requested from the individual resource endpoints (e.g. the metadata for a single batch job).
Charset
If not negotiated otherwise with HTTP Content Negotiation (Accept-Charset header), services use UTF-8 as the default charset.
The API is designed in a way that for most resources, such as collections and processes, a set of links can be added. These can be alternate representations such as data discovery via OGC WCS or OGC CSW, references to a license, references to actual raw data for downloading, detailed information about pre-processing and more. Clients should allow users to follow the links.
Whenever links are utilized in the API, the description explains which relation (rel property) types are commonly used.
A list of standardized link relations types is provided by IANA and the API tries to align whenever feasible.
Some very common relation types - usually not mentioned explicitly in the description of links fields - are:
self: Refers to the location that the resource can be (permanently) found online. This is particularly useful when the data is made available offline, so that the downstream user knows the source of the data.alternate: An alternative representation of the resource, may it be another metadata standard the data is available in or simply a human-readable version in HTML or PDF.about: A resource that is related to or further explains the resource, e.g. a user guide.canonical: This relation type usually points to a publicly accessible and more long-lived URL for a resource that otherwise often requires (Bearer) authentication with a short-lived token. This way the exposed resources can be used by non-openEO clients without additional authentication steps. For example, a shared user-defined process or batch job results could be exposed via a canonical link. If a URL should be publicly available to everyone, it can simply a user-specific URL, e.g.https://openeo.example/processes/john_doe/ndvi. For resources that should only be accessible to a certain group of user, a signed URL could be given, e.g.https://openeo.example/processes/81zjh1tc2pt52gbx/ndvi.
Generally, it is RECOMMENDED adding descriptive titles (property title) and media type information (property type) for a better user experience.
The success of requests MUST be indicated using HTTP status codes according to RFC 7231.
If the API responds with a status code between 100 and 399 the back-end indicates that the request has been handled successfully.
In general an error is communicated with a status code between 400 and 599. Client errors are defined as a client passing invalid data to the service and the service correctly rejecting that data. Examples include invalid credentials, incorrect parameters, unknown versions, or similar. These are generally "4xx" HTTP error codes and are the result of a client passing incorrect or invalid data. Client errors do not contribute to overall API availability.
Server errors are defined as the server failing to correctly return in response to a valid client request. These are generally "5xx" HTTP error codes. Server errors do contribute to the overall API availability. Calls that fail due to rate limiting or quota failures MUST NOT count as server errors.
JSON error object
A JSON error object SHOULD be sent with all responses that have a status code between 400 and 599.
{
"id": "936DA01F-9ABD-4D9D-80C7-02AF85C822A8",
"code": "SampleError",
"message": "A sample error message.",
"url": "https://openeo.example/docs/errors/SampleError"
}
Sending code and message is REQUIRED.
A back-end MAY add a free-form
id(unique identifier) to the error response to be able to log and track errors with further non-disclosable details.The
codeis either one of the standardized textual openEO error codes or a proprietary error code.The
messageexplains the reason the server is rejecting the request. For "4xx" error codes the message explains how the client needs to modify the request.By default, the message MUST be in English. Content Negotiation is used to localize the error messages: If an
Accept-Languageheader is sent by the client and a translation is available, the message should be translated accordingly, and theContent-Languageheader must be present in the response. See "How to localize your API" for more information.urlis an OPTIONAL attribute and contains a link to a resource that is explaining the error and potential solutions in-depth.
Standardized status codes
The openEO API usually uses the following HTTP status codes for successful requests:
- 200 OK: Indicates a successful request with a response body being sent.
- 201 Created
Indicates a successful request that successfully created a new resource. Sends a
Locationheader to the newly created resource without a response body. - 202 Accepted Indicates a successful request that successfully queued the creation of a new resource, but it has not been created yet. The response is sent without a response body.
- 204 No Content: Indicates a successful request without a response body being sent.
The openEO API reuses commonly used HTTP status codes for failed requests:
400 Bad Request: The back-end responds with this error code whenever the error has its origin on client side and no other HTTP status code in the 400 range is suitable.
401 Unauthorized: The client did not provide any authentication details for a resource requiring authentication or the provided authentication details are not correct.
403 Forbidden: The client did provide correct authentication details, but the privileges/permissions of the provided credentials do not allow requesting the resource.
404 Not Found: The resource specified by the path does not exist. One of the resources belonging to the specified identifiers are not available at the back-end. Note: Unsupported endpoints MAY also return an HTTP status code 501.
500 Internal Server Error: The error has its origin on server side and no other status code in the 500 range is suitable.
501 Not Implemented: The requested endpoint is specified by the openEO API, but is not implemented (yet) by the back-end. Note: Unsupported endpoints MAY also return HTTP status code 404.
If a HTTP status code in the 400 range is returned, the client SHOULD modify the request and repeat the request. For HTTP status code in the 500 range, the client MAY repeat the same request later.
All HTTP status codes defined in RFC 7231 in the 400 and 500 ranges can be used as openEO error code in addition to the most used status codes mentioned here. Responding with openEO error codes 400 and 500 SHOULD be avoided in favor of any more specific standardized or proprietary openEO error code.
The openEO API offers two forms of authentication by default:
- OpenID Connect (recommended) at
GET /credentials/oidc - Basic at
GET /credentials/basic
After authentication with any of the methods listed above, the tokens obtained during the authentication workflows can be sent to protected endpoints in subsequent requests.
Further authentication methods MAY be added by back-ends.
Bearer
A Bearer token can be provided in two different formats:
JSON Web Token (JWT) - RECOMMENDED
- Conformance class:
https://api.openeo.org/1.3.0/authentication/jwt
The Bearer token is an access token in JWT format as defined in RFC 7519. For openEO, it MUST include the issuer in the
issclaim although being optional in RFC 7519. If the concept of an issuer does not exist in an authentication method (e.g. in HTTP Basic), implementations could use the endpoint for Basic Authentication as the issuer, for example.openEO backend implementations MUST signal their support for JWT by listing the given conformance class. Likewise, openEO clients SHOULD only use JWT when the openEO backend lists the conformance class.
- Conformance class:
openEO Tokens - DEPRECATED
- Conformance class: None
The Bearer Token is constructed from the authentication method, a provider ID (if available) and the access token. All separated by a forward slash
/.Examples (replace
TOKENwith the actual access token):- Basic authentication (no provider ID available):
basic//TOKEN - OpenID Connect (provider ID is
ms):oidc/ms/TOKEN. For OpenID Connect, the provider ID corresponds to the value specified foridfor each provider inGET /credentials/oidc.
All openEO backends MUST accept this method for backward compatibility until version 2.0 of the specification.
The access tokens provided by the identity provider do not include the prefix that includes the authentication method and provider ID. The Bearer Token sent to the openEO backend MUST have the prefix, e.g.
basic//for Basic authentication. This means that the clients have to prepend the prefix.
JWT and openEO tokens can be distinguished by the presence of a slash / in the token, which JWT can never contain due to the Base64 encoding.
bearerJWT or openEONote: Although it is possible to request several public endpoints for capabilities and discovery that do not require authorization, it is RECOMMENDED that clients (re-)request the public endpoints that support Bearer authentication with the Bearer token once available to also retrieve any private data that is made available specifically for the authenticated user. This may require that clients clear any cached data they retrieved from public endpoints before.
Cross-origin resource sharing (CORS) is a mechanism that allows restricted resources [...] on a web page to be requested from another domain outside the domain from which the first resource was served. [...] CORS defines a way in which a browser and server can interact to determine whether it is safe to allow the cross-origin request. This allows for more freedom and functionality than purely same-origin requests, but is more secure than simply allowing all cross-origin requests.
Source: https://en.wikipedia.org/wiki/Cross-origin_resource_sharing
openEO-based back-ends are usually hosted on a different domain / host than the client that is requesting data from the back-end. Therefore, most requests to the back-end are blocked by all modern browsers. This leads to the problem that the JavaScript library and any browser-based application can not access back-ends. Therefore, all back-end providers SHOULD support CORS to enable browser-based applications to access back-ends. CORS is a recommendation of the W3C organization. The following chapters explain how back-end providers can implement CORS support.
Tip: Most servers can send the required headers and the responses to the OPTIONS requests automatically for all endpoints. Otherwise, a proxy server may be used to add the headers and OPTIONS responses.
The following headers MUST be included with every response:
| Name | Description | Example |
|---|---|---|
| Access-Control-Allow-Origin | Allowed origin for the request, including protocol, host and port or * for all origins. Returning the value * to allow requests from browser-based implementations is RECOMMENDED. |
* |
| Access-Control-Expose-Headers | Some endpoints require sending additional HTTP response headers such as OpenEO-Identifier and Location. To make these headers available to browser-based clients, they MUST be white-listed with this CORS header. The following HTTP headers are white-listed by browsers and MUST NOT be included: Cache-Control, Content-Language, Content-Length, Content-Type, Expires, Last-Modified and Pragma. At least the following headers MUST be listed in this version of the openEO API: Link, Location, OpenEO-Costs and OpenEO-Identifier. |
Link, Location, OpenEO-Costs, OpenEO-Identifier |
Example request and response
Request:
POST /api/v1/jobs HTTP/1.1
Host: openeo.example
Origin: https://company.example:8080
Authorization: Bearer basic//ZXhhbXBsZTpleGFtcGxl
Response:
HTTP/1.1 201 Created
Access-Control-Allow-Origin: *
Access-Control-Expose-Headers: Location, OpenEO-Identifier, OpenEO-Costs, Link
Content-Type: application/json
Location: https://openeo.example/api/v1/jobs/abc123
OpenEO-Identifier: abc123
All endpoints defined in the API specification must additionally respond to the OPTIONS HTTP method. This is a response for the preflight requests made by web browsers before sending the actual request (e.g. POST /jobs). It needs to respond with a status code of 204 and no response body.
In addition to the HTTP headers shown in the table above, the following HTTP headers MUST be included with every response to an OPTIONS request:
| Name | Description | Example |
|---|---|---|
| Access-Control-Allow-Headers | Comma-separated list of HTTP headers allowed to be sent with the actual (non-preflight) request. MUST contain at least Authorization if any kind of authorization is implemented by the back-end. |
Authorization, Content-Type |
| Access-Control-Allow-Methods | Comma-separated list of HTTP methods allowed to be requested. Back-ends MUST list all implemented HTTP methods for the endpoint. | OPTIONS, GET, POST, PATCH, PUT, DELETE |
| Content-Type | SHOULD return the content type delivered by the request that the permission is requested for. | application/json |
Example request and response
Request:
OPTIONS /api/v1/jobs HTTP/1.1
Host: openeo.example
Origin: https://company.example:8080
Access-Control-Request-Method: POST
Access-Control-Request-Headers: Authorization, Content-Type
Note that the Access-Control-Request-* headers are automatically attached to the requests by the browsers.
Response:
HTTP/1.1 204 No Content
Access-Control-Allow-Origin: *
Access-Control-Allow-Methods: OPTIONS, GET, POST, PATCH, PUT, DELETE
Access-Control-Allow-Headers: Authorization, Content-Type
Access-Control-Expose-Headers: Location, OpenEO-Identifier, OpenEO-Costs, Link
Content-Type: application/json
A process is an operation that performs a specific task on a set of parameters and returns a result. An example is computing a statistical operation, such as mean or median, on selected EO data. A process is similar to a function or method in programming languages. In openEO, processes are used to build a chain of processes (process graph), which can be applied to EO data to derive your own findings from the data.
A predefined process is a process provided by the back-end. There is a set of predefined processes by openEO to improve interoperability between back-ends. Back-ends SHOULD follow these specifications whenever possible. Not all processes need to be implemented by all back-ends. See the process reference for predefined processes.
A user-defined process is a process defined by the user. It can directly be part of another process graph or be stored as custom process on a back-end. Internally, it is a process graph with a variety of additional metadata.
A process graph chains specific process calls from the set of predefined and user-defined processes together. A process graph itself can be stored as a (user-defined) process again. Similarly to scripts in the context of programming, process graphs organize and automate the execution of one or more processes that could alternatively be executed individually. In a process graph, processes need to be specific, i.e. concrete values or "placeholders" for input parameters need to be specified. These values can be scalars, arrays, objects, references to parameters or previous computations or other process graphs.
Back-ends and users MAY define new proprietary processes for their domain.
Back-end providers MUST follow the schema for predefined processes as in GET /processes to define new processes. This includes:
- Choosing a intuitive process id, consisting of only letters (a-z), numbers and underscores. It MUST be unique across the predefined processes.
- Defining the parameters and their exact (JSON) schemes.
- Specifying the return value of a process also with a (JSON) schema.
- Providing examples or compliance tests.
- Trying to make the process universally usable so that other back-end providers or openEO can adopt it.
Users MUST follow the schema for user-defined processes as in GET /process_graphs/{process_graph_id} to define new processes. This includes:
- Choosing a intuitive name as process id, consisting of only letters (a-z), numbers and underscores. It MUST be unique per user across the user-defined processes.
- Defining the algorithm as a process graph.
- Optionally, specifying the additional metadata for processes.
If new process are potentially useful for other back-ends the openEO consortium is happily accepting pull requests to include them in the list of predefined processes.
Schemas
Each process parameter and the return values of a process define a schema that the value MUST comply to. The schemas are based on JSON Schema draft-07.
Multiple custom keywords have been defined:
subtypefor more fine-grained data-types than JSON Schema supports.dimensionsto further define the dimension types required if thesubtypeisdatacube.parametersto specify the parameters of a process graph if thesubtypeisprocess-graph.returnsto describe the return value of a process graph if thesubtypeisprocess-graph.
Subtypes
JSON Schema allows to specify only a small set of native data types (string, boolean, number, integer, array, object, null).
To support more fine grained data types, a custom JSON Schema keyword has been defined: subtype.
It works similarly as the JSON Schema keyword format
and standardizes a number of openEO related data types that extend the native data types, for example:
bounding-box (object with at least west, south, east and north properties),
date-time (string representation of date and time following RFC 3339),
datacube (a datacube with dimensions), etc.
The subtypes should be re-used in process schema definitions whenever suitable.
If a general data type such as string or number is used in a schema, all subtypes with the same parent data type can be passed, too.
Clients should offer make passing subtypes as easy as passing a general data type.
For example, a parameter accepting strings must also allow passing a string with subtype date and thus clients should encourage this by also providing a date-picker.
A list of predefined subtypes is available as JSON Schema in openeo-processes.
As defined above, a process graph is a chain of processes with explicit values for their parameters. Technically, a process graph is defined to be a graph of connected processes with exactly one node returning the final result:
<ProcessGraph> := {
"<ProcessNodeIdentifier>": <ProcessNode>,
...
}
<ProcessNodeIdentifier> is a unique key within the process graph that is used to reference (the return value of) this process in arguments of other processes. The identifier is unique only strictly within itself, excluding any parent and child process graphs. Process node identifiers are also strictly scoped and can not be referenced from child or parent process graphs. Circular references are not allowed.
Note: We provide a non-binding JSON Schema for basic process graph validation.
Processes (Process Nodes)
A single node in a process graph (i.e. a specific instance of a process) is defined as follows:
<ProcessNode> := {
"process_id": <string>,
"namespace": <string> / null,
"description": <string>,
"arguments": <Arguments>,
"result": true / false
}
A process node MUST always contain key-value-pairs named process_id and arguments. It MAY contain a description.
process_id MUST be a valid process ID in the namespace given. Clients SHOULD warn the user if a user-defined process is added with the same identifier as one of the predefined process.
In the following, "end node" (also known as "leaf node") defines a node that is not referenced by any other node in the same process graph. The "root process graph" is the outermost process graph, which is not part of any other process graph.
A "result node" is a node (often an end node, but that's not required) that defines the return value of the process graph and has the result flag set to true. Exactly one of the nodes in a map of processes MUST have the result flag set to true, all the other nodes can omit it as the default value is false. Each child process graph MUST specify its own result node. The root process graph MUST also specify a result node although not strictly needed in all use cases.
Having a result node is important as multiple end nodes are possible and in many use cases it is important to identify a specific return value for the process graph that is passed to other processes. The result node is not necessarily an end node.
Arguments
A process can have an arbitrary number of arguments. Their name and value are specified in the process specification as an object of key-value pairs:
<Arguments> := {
"<ParameterName>": <string|number|boolean|null|array|object|ResultReference|UserDefinedProcess|ParameterReference>
}
Notes:
The specified data types are the native data types supported by JSON, except for
ResultReference,UserDefinedProcessandParameterReference.Objects are not allowed to have keys with the following reserved names:
from_node, except for objects of typeResultReferenceprocess_graph, except for objects of typeUserDefinedProcessfrom_parameter, except for objects of typeParameterReference
Arrays and objects can also contain a
ResultReference, aUserDefinedProcessor aParameterReference. So back-ends must fully traverse the process graphs, including all children.
Accessing results of other process nodes
A value of type <ResultReference> is an object with a key from_node and a <ProcessNodeIdentifier> as corresponding value:
<ResultReference> := {
"from_node": "<ProcessNodeIdentifier>"
}
This tells the back-end that the process expects the result (i.e. the return value) from another process node to be passed as argument.
The <ProcessNodeIdentifier> is strictly scoped and can only reference nodes from within the same process graph, not child or parent process graphs.
Child processes
Some processes can run child processes, which is similar to the concept that other programming languages call callbacks or lambda functions. Each child process is simply a user-defined process again and can in theory be arbritarily complex.
A very simple example would be to calculate the absolute value of each pixel in a data cube.
This can be achieved in openEO by using the apply process which gets the absolute process passed as child process.
In this example, the "child" processes consists of a single process absolute, but it can also be a more complex computation such as an NDVI or a prediciton based on a machine learning model.
Example:
A <UserDefinedProcess> argument MUST at least consist of an object with a key process_graph.
Optionally, it can also be described with the same additional properties available for predefined processes such as an id, parameters, return values etc.
When embedded in a process graph, these additional properties of a user-defined process are usually not used, except for validation purposes.
<UserDefinedProcess> := {
"process_graph": <ProcessGraph>,
...
}
Accessing process parameters
A "parent" process that works with a child process can make so called process graph parameters
available to the "child" logic.
Processes in the "child" process graph can access these parameters by passing a ParameterReference object as argument.
It is an object with key from_parameter specifying the name of the process graph parameter:
<ParameterReference> := {
"from_parameter": "<ParameterReferenceName>"
}
The parameter names made available for <ParameterReferenceName> are defined and passed to the process graph by one of the parent entities.
The parent could be a process (such as apply or reduce_dimension) or something else that executes a process graph (a secondary web service for example).
If the parent is a process, the parameter are defined in the parameters property of the corresponding JSON Schema.
In case of the example given above, the parameter process in the process apply defines two process graph parameters: x (the value of each pixel that will be processed) and context (additional data passed through from the user).
The process absolute expects an argument with the same name x.
The process graph for the example would look as follows:
{
"process_id": "apply",
"arguments": {
"data": {"from_node": "loadcollection1"}
"process": {
"process_graph": {
"abs1": {
"process_id": "absolute",
"arguments": {
"x": {"from_parameter": "x"}
},
"result": true
}
}
}
}
}
loadcollection1 would be a result from another process, which is not part of this example.
Important: <ParameterReferenceName> is less strictly scoped than <ProcessNodeIdentifier>.
<ParameterReferenceName> can be any parameter from the process graph or any of its parents.
The value for the parameter MUST be resolved as follows:
- In general the most specific parameter value is used. This means the parameter value is resolved starting from the current scope and then checking each parent for a suitable parameter value until a parameter values is found or the "root" process graph has been reached.
- In case a parameter value is not available, the most unspecific default value from the process graph parameter definitions are used. For example, if default values are available for the root process graph and all children, the default value from the root process graph is used.
- If no default values are available either, the error
ProcessParameterMissingmust be thrown.
Full example for an EVI computation
Deriving minimum EVI (Enhanced Vegetation Index) measurements over pixel time series of Sentinel-2 imagery. The root process graph in blue, child process graphs in yellow:
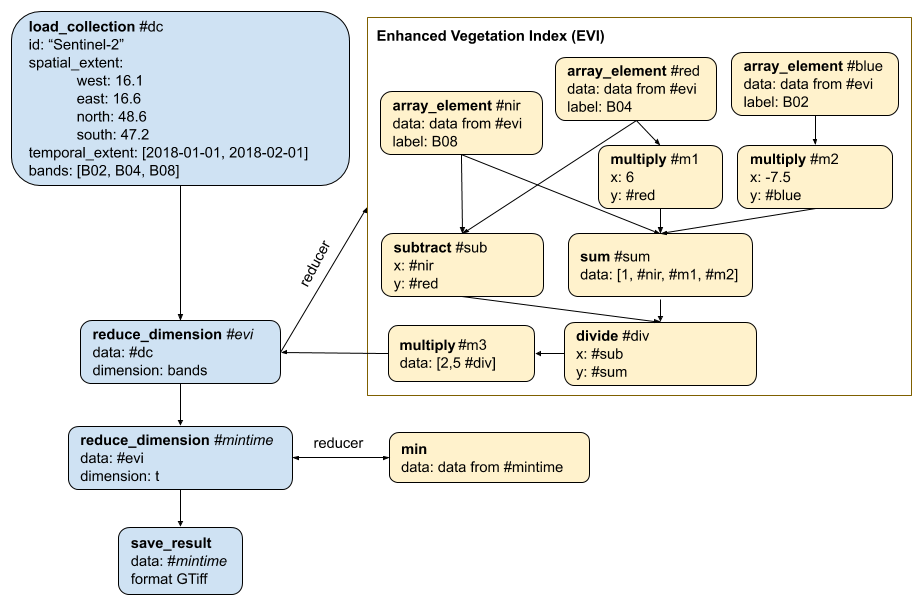
The process graph for the algorithm: pg-evi-example.json
Processes can run in three different ways:
Results can be pre-computed by creating a batch job. They are submitted to the back-end's processing system, but will remain inactive until explicitly put into the processing queue. They will run only once and store results after execution. Results can be downloaded. Batch jobs are typically time consuming and user interaction is not possible although log files are generated for them. This is the only mode that allows to get an estimate about time, volume and costs beforehand.
A more dynamic way of processing and accessing data is to create a secondary web service. They allow web-based access using different protocols such as OGC WMS, OGC WCS, OGC API - Features or XYZ tiles. Some protocols such as the OGC WMS or XYZ tiles allow users to change the viewing extent or level of detail (zoom level). Therefore, computations often run on demand so that the requested data is calculated during the request. Back-ends should make sure to cache processed data to avoid additional/high costs and reduce waiting times for the user.
Processes can also be executed on-demand (i.e. synchronously). Results are delivered with the request itself and no job is created. Only lightweight computations, for example previews, should be executed using this approach as timeouts are to be expected for long-polling HTTP requests.
Validation
Process graph validation is a quite complex task. There's a JSON schema for basic process graph validation. It checks the general structure of a process graph, but only checking against the schema is not fully validating a process graph. Note that this JSON Schema is probably good enough for a first version, but should be revised and improved for production. There are further steps to do:
- Validate whether there's exactly one
result: trueper process graph. - Check whether the process names that are referenced in the field
process_idare actually available in the correspondingnamespace. - Validate all arguments for each process against the JSON schemas that are specified in the corresponding process specifications.
- Check whether the values specified for
from_nodehave a corresponding node in the same process graph. - Validate whether the return value and the arguments requesting a return value with
from_nodeare compatible. - Check the content of arrays and objects. These could include parameter and result references (
from_node,from_parameteretc.).
Execution
To process the process graph on the back-end you need to go through all nodes/processes in the list and set for each node to which node it passes data and from which it expects data. In another iteration the back-end can find all start nodes for processing by checking for zero dependencies.
You can now start and execute the start nodes (in parallel, if possible). Results can be passed to the nodes that were identified beforehand. For each node that depends on multiple inputs you need to check whether all dependencies have already finished and only execute once the last dependency is ready.
Please be aware that the result node (result set to true) is not necessarily the last node that is executed. The author of the process graph may choose to set a non-end node to the result node!
General information about the API implementation and other supported capabilities provided by the back-end.
Information about the back-end
Lists general information about the back-end, including which version and endpoints of the openEO API are supported. May also include billing information.
Authorizations:
Responses
Response Schema: application/json
| api_version required | string Value: "1.3.0" Version number of the openEO API specification the back-end implements. |
| backend_version required | string Version number of the back-end implementation. Every change on back-end side MUST cause a change of the version number. |
| stac_version required | string (stac_version) ^(0\.9.\d+|1\.\d+.\d+) The version of the STAC specification, which MAY not be equal to the STAC API version. The openEO API allows for the STAC versions 1.x.x (RECOMMENDED) and 0.9.x (DEPRECATED). |
| type required | string Value: "Catalog" |
| id required | string Identifier for the service.
This field originates from STAC and is used as unique identifier for the STAC catalog available at |
| title required | string The name of the service. |
| description required | string <commonmark> A description of the service, which allows the service provider to introduce the user to its service. CommonMark 0.29 syntax MAY be used for rich text representation. |
| conformsTo required | Array of strings <uri> (conformsTo) [ items <uri > ] Lists all conformance classes specified in various standards that the implementation conforms to. Conformance classes are commonly used in all OGC API standards and the STAC API specification. The general openEO conformance class is |
| production | boolean (production) Default: false Specifies whether the implementation is ready to be used in production use ( |
required | Array of objects (Endpoint) Lists all supported endpoints. Supported are all endpoints, which are implemented, return usually a 2XX or 3XX HTTP status code and are fully compatible to the API specification. An entry for this endpoint (path |
object (Billing) Billing related data, e.g. the currency used or available plans to process jobs. This property MUST be specified if the back-end uses any billing related API functionalities, e.g. budgeting or estimates. The absence of this property does not mean the back-end is necessarily free to use for all. Providers may choose to bill users outside of the API, e.g. with a monthly fee that is not depending on individual API interactions. | |
required | Array of objects (Link) Links related to this service, e.g. the homepage of the service provider or the terms of service. It is highly RECOMMENDED to provide links with the
following
For additional relation types see also the lists of common relation types in openEO. |
Response samples
- 200
- 4XX
- 5XX
{- "api_version": "1.3.0",
- "backend_version": "1.1.2",
- "stac_version": "1.1.0",
- "type": "Catalog",
- "id": "cool-eo-cloud",
- "title": "Example Cloud Corp.",
- "description": "This service is provided to you by [Example Cloud Corp.](https://cloud.example). It implements the full openEO API and allows to process a range of 999 EO data sets, including \n\n* Sentinel 1/2/3 and 5\n* Landsat 7/8\n\nA free plan is available to test the service. For further information please contact our customer service at [support@cloud.example](mailto:support@cloud.example).",
- "production": false,
- "endpoints": [
- {
- "path": "/collections",
- "methods": [
- "GET"
]
}, - {
- "path": "/collections/{collection_id}",
- "methods": [
- "GET"
]
}, - {
- "path": "/processes",
- "methods": [
- "GET"
]
}, - {
- "path": "/jobs",
- "methods": [
- "GET",
- "POST"
]
}, - {
- "path": "/jobs/{job_id}",
- "methods": [
- "GET",
- "DELETE",
- "PATCH"
]
}
], - "billing": {
- "currency": "USD",
- "default_plan": "free",
- "plans": [
- {
- "name": "free",
- "description": "Free plan. Calculates one tile per second and a maximum amount of 100 tiles per hour.",
- "paid": false
}, - {
- "name": "premium",
- "description": "Premium plan. Calculates unlimited tiles and each calculated tile costs 0.003 USD.",
- "paid": true
}
]
}, - "links": [
- {
- "rel": "about",
- "type": "text/html",
- "title": "Homepage of the service provider"
}, - {
- "rel": "terms-of-service",
- "type": "text/html",
- "title": "Terms of Service"
}, - {
- "rel": "privacy-policy",
- "type": "text/html",
- "title": "Privacy Policy"
}, - {
- "rel": "create-form",
- "type": "text/html",
- "title": "User Registration"
}, - {
- "rel": "recovery-form",
- "type": "text/html",
- "title": "Reset Password"
}, - {
- "rel": "version-history",
- "type": "application/json",
- "title": "List of supported openEO versions"
}, - {
- "rel": "conformance",
- "type": "application/json",
- "title": "OGC Conformance Classes"
}, - {
- "rel": "data",
- "type": "application/json",
- "title": "List of Datasets"
}, - {
- "rel": "web-editor",
- "type": "text/html",
- "title": "openEO Web Editor",
- "version": "0.14.0"
}
]
}Supported openEO versions
Lists all implemented openEO versions supported by the service provider. This endpoint is the Well-Known URI (see RFC 5785) for openEO.
This allows a client to easily identify the most recent openEO implementation it supports. By default, a client SHOULD connect to the most recent production-ready version it supports. If not available, the most recent supported version of all versions SHOULD be connected to. Clients MAY let users choose to connect to versions that are not production-ready or outdated. The most recent version is determined by comparing the version numbers according to rules from Semantic Versioning, especially §11. Any pair of API versions in this list MUST NOT be equal according to Semantic Versioning.
The Well-Known URI is the entry point for clients and users, so make
sure it is permanent and easy to use and remember. Clients MUST NOT
require the well-known path (/.well-known/openeo) in the URL that is
specified by a user to connect to the back-end.
For clients, the usual behavior SHOULD follow these steps:
- The user provides a URI, which may consist of a scheme (protocol), an authority (host, port) and a path.
- The client parses the URI and appends
/.well-knwon/openeoto the path. Make sure to correctly handle leading/trailing slashes. - Send a request to the new URI. A. On success: Detect the most suitable API instance/version (see above) and read the capabilities from there. B. On failure: Directly try to read the capabilities from the original URI given by the user.
This URI MUST NOT be versioned as the other endpoints.
If your API is available at https://openeo.example/api/v1, and
you instruct your API users to use https://openeo.example as connection URI,
the Well-Known URI SHOULD be located at https://openeo.example/.well-known/openeo.
The Well-Known URI is usually directly located at the top-level, but it is not a
requirement. For example, https://openeo.example/eo/.well-known/openeo is also allowed.
Clients MAY get additional information (e.g. title or description) about
a back-end from the most recent version that has the production flag
set to true.
Authorizations:
Responses
Response Schema: application/json
required | Array of objects (API Instance) |
Response samples
- 200
- 4XX
- 5XX
{- "versions": [
]
}Supported file formats
Lists supported input and output file formats. Input file formats specify which file a back-end can read from. Output file formats specify which file a back-end can write to.
The response to this request is an object listing all available input and output file formats separately with their parameters and additional data. This endpoint does not include the supported secondary web services.
Note: Format names and parameters MUST be fully aligned with the GDAL codes if available, see GDAL Raster Formats and OGR Vector Formats. It is OPTIONAL to support all output format parameters supported by GDAL. Some file formats not available through GDAL may be defined centrally for openEO. Custom file formats or parameters MAY be defined.
The format descriptions MUST describe how the file formats relate to data cubes. Input file formats MUST describe how the files have to be structured to be transformed into data cubes. Output file formats MUST describe how the data cubes are stored at the back-end and how the resulting file structure looks like.
Back-ends MUST NOT support aliases, for example it is not allowed to
support geotiff instead of gtiff. Nevertheless, openEO Clients MAY
translate user input for convenience (e.g. translate geotiff to
gtiff). Also, for a better user experience the back-end can specify a
title.
Format names MUST be accepted in a case insensitive manner throughout the API.
Authorizations:
Responses
Response Schema: application/json
required | object (Input File Formats) Map of supported input file formats, i.e. file formats a back-end can read from. The property keys are the file format names that are used by clients and users, for example in process graphs. |
required | object (Output File Formats) Map of supported output file formats, i.e. file formats a back-end can write to. The property keys are the file format names that are used by clients and users, for example in process graphs. |
Response samples
- 200
- 4XX
- 5XX
{- "output": {
- "GTiff": {
- "title": "GeoTiff",
- "description": "Export to GeoTiff. Does not support cloud-optimized GeoTiffs (COGs) yet.",
- "gis_data_types": [
- "raster"
], - "parameters": {
- "tiled": {
- "type": "boolean",
- "description": "This option can be used to force creation of tiled TIFF files [true]. By default [false] stripped TIFF files are created.",
- "default": false
}, - "compress": {
- "type": "string",
- "description": "Set the compression to use.",
- "default": "NONE",
- "enum": [
- "JPEG",
- "LZW",
- "DEFLATE",
- "NONE"
]
}, - "jpeg_quality": {
- "type": "integer",
- "description": "Set the JPEG quality when using JPEG.",
- "minimum": 1,
- "maximum": 100,
- "default": 75
}
}, - "links": [
- {
- "rel": "about",
- "title": "GDAL on the GeoTiff file format and storage options"
}
]
}, - "GPKG": {
- "title": "OGC GeoPackage",
- "gis_data_types": [
- "raster",
- "vector"
], - "parameters": {
- "version": {
- "type": "string",
- "description": "Set GeoPackage version. In AUTO mode, this will be equivalent to 1.2 starting with GDAL 2.3.",
- "enum": [
- "auto",
- "1",
- "1.1",
- "1.2"
], - "default": "auto"
}
}, - "links": [
- {
- "rel": "about",
- "title": "GDAL on GeoPackage for raster data"
}, - {
- "rel": "about",
- "title": "GDAL on GeoPackage for vector data"
}
]
}
}, - "input": {
- "GPKG": {
- "title": "OGC GeoPackage",
- "gis_data_types": [
- "raster",
- "vector"
], - "parameters": {
- "table": {
- "type": "string",
- "description": "**RASTER ONLY.** Name of the table containing the tiles. If the GeoPackage dataset only contains one table, this option is not necessary. Otherwise, it is required."
}
}, - "links": [
- {
- "rel": "about",
- "title": "GDAL on GeoPackage for raster data"
}, - {
- "rel": "about",
- "title": "GDAL on GeoPackage for vector data"
}
]
}
}
}Conformance classes this API implements
Lists all conformance classes specified in various standards that the implementation conforms to. Conformance classes are commonly used in all OGC API standards and the STAC API specification. openEO adds relatively broadly defined conformance classes, especially for the extensions. Otherwise, the implemented functionality can usually be retrieved from the capabilities in openEO.
The general openEO conformance class is https://api.openeo.org/1.3.0.
See the individual openEO API extensions for their conformance classes.
The conformance classes listed at this endpoint and listed in the
corresponding conformsTo property in GET / MUST be equal.
More details:
- STAC API, especially the conformance class "STAC API - Collections"
- OGC API standards
Authorizations:
Responses
Response Schema: application/json
| conformsTo required | Array of strings <uri> (conformsTo) [ items <uri > ] Lists all conformance classes specified in various standards that the implementation conforms to. Conformance classes are commonly used in all OGC API standards and the STAC API specification. The general openEO conformance class is |
Response samples
- 200
- 4XX
- 5XX
Supported UDF runtimes
Lists the supported runtimes for user-defined functions (UDFs), which includes either the programming languages including version numbers and available libraries including version numbers or docker containers.
Authorizations:
Responses
Response Schema: application/json
non-emptyadditional property | object |
Response samples
- 200
- 4XX
- 5XX
{- "PHP": {
- "title": "PHP v7.x",
- "description": "Just an example how to reference a docker image.",
- "experimental": true,
- "type": "docker",
- "docker": "openeo/udf-php7",
- "default": "latest",
- "tags": [
- "latest",
- "7.3.1",
- "7.3",
- "7.2"
],
}, - "R": {
- "title": "R v3.x for Statistical Computing",
- "description": "R programming language with `Rcpp` and `rmarkdown` extensions installed.",
- "type": "language",
- "default": "3.5.2",
- "versions": {
- "3.1.0": {
- "deprecated": true,
- "libraries": {
- "Rcpp": {
- "version": "1.0.10",
}, - "rmarkdown": {
- "version": "1.7.0",
}
}
}, - "3.5.2": {
- "libraries": {
- "Rcpp": {
- "version": "1.2.0",
}, - "rmarkdown": {
- "version": "1.7.0",
}
}
}
}
}
}Supported secondary web service protocols
Lists supported secondary web service protocols such as OGC WMS, OGC WCS, OGC API - Features or XYZ tiles. The response is an object of all available secondary web service protocols with their supported configuration settings and expected process parameters.
- The configuration settings for the service SHOULD be defined upon creation of a service and the service will be set up accordingly.
- The process parameters SHOULD be referenced (with a
from_parameterreference) in the user-defined process that is used to compute web service results. The appropriate arguments MUST be provided to the user-defined process, usually at runtime from the context of the web service. For example, a map service such as a WMS would need to inject the spatial extent into the user-defined process so that the back-end can compute the corresponding tile correctly.
To improve interoperability between back-ends common names for the services SHOULD be used, e.g. the abbreviations used in the official OGC Schema Repository for the respective services.
Service names MUST be accepted in a case insensitive manner throughout the API.
Authorizations:
Responses
Response Schema: application/json
additional property | object (Service Type) |
Response samples
- 200
- 4XX
- 5XX
{- "WMS": {
- "title": "OGC Web Map Service",
- "configuration": {
- "version": {
- "type": "string",
- "description": "The WMS version offered to consumers of the service.",
- "default": "1.3.0",
- "enum": [
- "1.1.1",
- "1.3.0"
]
}
}, - "process_parameters": [
- {
- "name": "layer",
- "description": "The layer name.",
- "schema": {
- "type": "string"
}, - "default": "roads"
}, - {
- "name": "spatial_extent",
- "description": "A bounding box in WGS84.",
- "schema": {
- "type": "object",
- "required": [
- "west",
- "south",
- "east",
- "north"
], - "properties": {
- "west": {
- "description": "West (lower left corner, coordinate axis 1).",
- "type": "number"
}, - "south": {
- "description": "South (lower left corner, coordinate axis 2).",
- "type": "number"
}, - "east": {
- "description": "East (upper right corner, coordinate axis 1).",
- "type": "number"
}, - "north": {
- "description": "North (upper right corner, coordinate axis 2).",
- "type": "number"
}
}
}
}
], - "links": [
- {
- "rel": "about",
- "title": "OGC Web Map Service Standard"
}
]
}, - "OGCAPI-FEATURES": {
- "title": "OGC API - Features",
- "description": "Exposes a OGC API - Features in version 1.0 of the specification (successor of OGC WFS 3.0).",
- "configuration": {
- "title": {
- "type": "string",
- "description": "The title for the OGC API - Features landing page"
}, - "description": {
- "type": "string",
- "description": "The description for the OGC API - Features landing page"
}, - "conformsTo": {
- "type": "array",
- "description": "The OGC API - Features conformance classes to enable for this service.\n\n`http://www.opengis.net/spec/ogcapi-features-1/1.0/conf/core` is always enabled.",
}
}, - "process_parameters": [ ],
- "links": [
- {
- "rel": "about",
- "title": "OGC Web Feature Service Standard"
}
]
}
}The following endpoints handle user profiles, accounting and authentication. See also Authentication. In general, the openEO API only defines a minimum subset of user management and accounting functionality. It allows to
- authenticate and authorize a user, which may include user registration with OpenID Connect,
- handle storage space limits (disk quota),
- manage billing, which includes to
- query the credit a user has available,
- estimate costs for certain operations (data processing and downloading),
- get information about produced costs,
- limit costs of certain operations.
Therefore, the API leaves some aspects open that have to be handled by the back-ends separately, including
- credentials recovery, e.g. retrieving a forgotten password
- user data management, e.g. changing the users payment details or email address
- payments, i.e. topping up credits for pre-paid services or paying for post-paid services
- other accounting related tasks, e.g. creating invoices,
- user registration (except for user registration with OpenID Connect).
OpenID Connect authentication
Lists the supported OpenID Connect providers (OP). OpenID Connect Providers MUST support OpenID Connect Discovery.
It is highly RECOMMENDED to implement OpenID Connect for public services in favor of Basic authentication.
openEO clients MUST use the access token as part of the Bearer token for authorization in subsequent API calls (see also the information about Bearer tokens in this document). Clients MUST NOT use the id token or the authorization code.
Back-ends MAY request user information (including Claims) from the OpenID Connect Userinfo endpoint using the access token (without the prefix described above). Therefore, both openEO client and openEO back-end are relying parties (clients) to the OpenID Connect Provider.
Authorizations:
Responses
Response Schema: application/json
required | Array of objects (OpenID Connect Provider) non-empty The first provider in this list is the default provider for authentication. Clients can either pre-select or directly use the default provider for authentication if the user does not specify a specific value. |
Response samples
- 200
- 4XX
- 5XX
{- "providers": [
- {
- "id": "egi",
- "title": "EGI (default)",
- "description": "Login with your academic account.",
- "scopes": [
- "openid",
- "profile",
- "email"
], - "default_clients": [
- {
- "id": "KStcUzD5AIUA",
- "grant_types": [
- "implicit",
- "authorization_code+pkce",
- "urn:ietf:params:oauth:grant-type:device_code+pkce",
- "refresh_token"
],
}
]
}, - {
- "id": "google",
- "title": "Google",
- "description": "Login with your Google Account.",
- "scopes": [
- "openid",
- "profile",
- "email",
- "earthengine"
], - "authorization_parameters": {
- "access_type": "offline"
}
}, - {
- "id": "ms",
- "title": "Microsoft",
- "description": "Login with your Microsoft or Skype Account.",
- "scopes": [ ]
}
]
}HTTP Basic authentication
Checks the credentials provided through HTTP Basic Authentication according to RFC 7617 and returns an access token in exchange for providing valid credentials.
The credentials (username and password) MUST be sent in the HTTP header
Authorization with type Basic and the Base64 encoded string
consisting of username and password separated by a double colon :. The
header would look as follows for username user and password pw:
Authorization: Basic dXNlcjpwdw==.
The access token has to be used in the Bearer token for authorization in subsequent API calls (see also the information about Bearer tokens in this document).
It is RECOMMENDED to implement this authentication method for non-public services only.
Authorizations:
Responses
Response Schema: application/json
| access_token required | string The access token to be used in the Bearer token for authorization in subsequent API calls (without the custom |
Response samples
- 200
- 4XX
- 5XX
{- "access_token": "b34ba2bdf9ac9ee1"
}Information about the authenticated user
Lists information about the authenticated user such as the user id. The endpoint MAY return the disk quota available to the user. The endpoint MAY also return links related to user management and the user profile, e.g. where payments are handled or the user profile could be edited. For back-ends that involve accounting, this service MAY also return the currently available money or credits in the currency the back-end is working with. This endpoint MAY be extended to fulfil the specification of the OpenID Connect UserInfo Endpoint.
Authorizations:
Responses
Response Schema: application/json
| user_id required | string^[\w\-\.~]+$ A unique user identifier specific to the back-end, which could either be chosen by a user or is automatically generated by the back-end during the registration process at the back-end.
It is meant to be used as an identifier in URIs (e.g. for sharing purposes), which is primarily used in machine-to-machine communication. Preferrably use the human-readable property |
| name | string The user name, a human-friendly displayable name. Could be the user's real name or a nickname. |
| default_plan | string Name of the single plan the user is currently subscribed to if any. |
object or null (User Storage) Information about the storage space available to the user. | |
| budget | number or null The remaining budget a user has available.
The value MUST be specified in the currency of the back-end.
The value SHOULD be set to |
Array of objects (Link) Links related to the user profile, e.g. where payments are handled or the user profile could be edited. Providing links with the following
For additional relation types see also the lists of common relation types in openEO. |
Response samples
- 200
- 4XX
- 5XX
{- "user_id": "john_doe",
- "name": "string",
- "default_plan": "free",
- "storage": {
- "free": 536870912,
- "quota": 1073741824
}, - "budget": 0,
- "links": [
- {
- "rel": "alternate",
- "type": "text/html",
- "title": "User profile"
}, - {
- "rel": "alternate",
- "type": "text/vcard",
- "title": "vCard of John Doe"
}, - {
- "rel": "related",
- "type": "text/html",
- "title": "Invoices"
}
]
}These endpoints allow to list the collections that are available at the back-end and can be used as data cubes for data processing.
For data discovery of Earth Observation Collections at the back-ends, openEO strives for compatibility with the specifications SpatioTemporal Asset Catalog (STAC) and OGC API - Features - Part 1: Core as far as possible. Implementing the data discovery endpoints of openEO also produces valid STAC API 1.x and OGC API - Features 1.x responses, including (partial) compatibility with their APIs.
The data discovery endpoints GET /collections and GET /collections/{collection_id} are compatible with OGC API - Features and STAC. Both specifications define additional endpoints that need to be implemented to be fully compatible. The additional endpoints can easily be integrated into an openEO API implementation. A rough list of actions for compatibility is available below, but please refer to their specifications to find out the full details.
Important: STAC specification and STAC API are different specifications and have different version numbers.
The openEO API allows for the
- STAC versions 1.x.x (RECOMMENDED) and 0.9.x (DEPRECATED), and
- STAC API versions 1.x.x (RECOMMENDED) and 0.9.x (DEPRECATED).
Content Extensions
STAC has several extensions that can be used to better describe your data. Clients and server are not required to implement all of them, so be aware that some clients may not be able to read all your metadata.
Some commonly used extensions that are relevant for datasets exposed through the openEO API are:
- Classification extension
- Data Cube extension (part of the openEO API)
- EO (Electro-Optical) extension
- Processing extension
- Projection extension
- Raster extension
- SAR extension
- Satellite extension
- Scientific Citation extension
Provide data for download
If you'd like to provide your data for download in addition to offering the cloud processing service, you can implement the full STAC API. Therefore, you can implement the endpoints GET /collections/{collection_id}/items and GET /collections/{collection_id}/items/{feature_id} to support retrieval of individual items. To benefit from the STAC ecosystem and allow searching for items you can also implement POST /search and GET /search. Further information can be found in the STAC API repository.
API Extensions
STAC API has several extensions that can be implemented on top of the openEO API to enrich the API functionality, e.g. for searching.
Basic metadata for all datasets
Lists available collections with at least the required information.
It is strongly RECOMMENDED to keep the response size small by
omitting larger optional values from the objects in collections (e.g. the
summaries and cube:dimensions properties).
To get the full metadata for a collection clients MUST
request GET /collections/{collection_id}.
This endpoint is compatible with STAC API 1.0.0 and later and OGC API - Features 1.0. STAC API extensions and STAC extensions can be implemented in addition to what is documented here.
Note: Although it is possible to request public collections without authorization, it is RECOMMENDED that clients (re-)request the collections with the Bearer token once available to also retrieve any private collections.
Authorizations:
query Parameters
| limit | integer >= 1 Example: limit=10 This parameter enables pagination for the endpoint and specifies the maximum number of
elements that arrays in the top-level object (e.g. collections, processes, batch jobs,
secondary services, log entries, etc.) are allowed to contain.
The Pagination is OPTIONAL: back-ends or clients may not support it. Therefore, it MUST be implemented in a way that clients not supporting pagination get all resources regardless. Back-ends not supporting pagination MUST return all resources. If the response is paginated, the |
Responses
Response Schema: application/json
required | Array of objects (Collection) |
required | Array of objects (links_pagination) Links related to this list of resources, for example links for pagination or alternative formats such as a human-readable HTML version. The links array MUST NOT be paginated. If pagination is implemented, the following
For additional relation types see also the lists of common relation types in openEO. |
Response samples
- 200
- 4XX
- 5XX
{- "collections": [
- {
- "stac_version": "1.0.0",
- "type": "Collection",
- "id": "Sentinel-2A",
- "title": "Sentinel-2A MSI L1C",
- "description": "Sentinel-2A is a wide-swath, high-resolution, multi-spectral imaging mission supporting Copernicus Land Monitoring studies, including the monitoring of vegetation, soil and water cover, as well as observation of inland waterways and coastal areas.",
- "license": "proprietary",
- "extent": {
- "spatial": {
- "bbox": [
- [
- -180,
- -56,
- 180,
- 83
]
]
}, - "temporal": {
- "interval": [
- [
- "2015-06-23T00:00:00Z",
- "2019-01-01T00:00:00Z"
]
]
}
}, - "keywords": [
- "copernicus",
- "esa",
- "msi",
- "sentinel"
], - "providers": [
- {
- "name": "European Space Agency (ESA)",
- "roles": [
- "producer",
- "licensor"
],
}, - {
- "name": "openEO",
- "roles": [
- "host"
],
}
], - "links": [
- {
- "rel": "license",
}
]
}, - {
- "stac_version": "1.0.0",
- "type": "Collection",
- "id": "MOD09Q1",
- "title": "MODIS/Terra Surface Reflectance 8-Day L3 Global 250m SIN Grid V006",
- "description": "The MOD09Q1 Version 6 product provides an estimate of the surface spectral reflectance of Terra MODIS Bands 1-2 corrected for atmospheric conditions such as gasses, aerosols, and Rayleigh scattering. Provided along with the two 250 m MODIS bands is one additional layer, the Surface Reflectance QC 250 m band. For each pixel, a value is selected from all the acquisitions within the 8-day composite period. The criteria for the pixel choice include cloud and solar zenith. When several acquisitions meet the criteria the pixel with the minimum channel 3 (blue) value is used. Validation at stage 3 has been achieved for all MODIS Surface Reflectance products.",
- "license": "proprietary",
- "extent": {
- "spatial": {
- "bbox": [
- [
- -180,
- -90,
- 180,
- 90
]
]
}, - "temporal": {
- "interval": [
- [
- "2000-02-01T00:00:00Z",
- null
]
]
}
},
}
], - "links": [
- {
- "rel": "alternate",
- "title": "openEO catalog (OGC Catalogue Services 3.0)"
}
]
}Full metadata for a specific dataset
Lists all information about a specific collection specified by the
identifier collection_id.
This endpoint is compatible with STAC API 1.0.0 and later and OGC API - Features 1.0. STAC API extensions and STAC extensions can be implemented in addition to what is documented here.
Note: Providing the Bearer token is REQUIRED for private collections.
Authorizations:
path Parameters
| collection_id required | string (collection_id) ^[\w\-\.~\/]+$ Example: Sentinel-2A Collection identifier |
Responses
Response Schema: application/json
| stac_version required | string (stac_version) ^(0\.9.\d+|1\.\d+.\d+) The version of the STAC specification, which MAY not be equal to the STAC API version. The openEO API allows for the STAC versions 1.x.x (RECOMMENDED) and 0.9.x (DEPRECATED). |
Array of Reference to a JSON Schema (string) or Reference to a core extension (STAC < 1.0.0-rc.1 only, DEPRECATED) (string) (stac_extensions) unique A list of implemented STAC extensions. The list contains URLs to the JSON Schema files it can be validated against. | |
| type | string Value: "Collection" For STAC versions >= 1.0.0-rc.1 this field is required. |
| id required | string (collection_id) ^[\w\-\.~\/]+$ A unique identifier for the collection, which MUST match the specified pattern. |
| title | string A short descriptive one-line title for the collection. |
| description required | string <commonmark> Detailed multi-line description to explain the collection. CommonMark 0.29 syntax MAY be used for rich text representation. |
| keywords | Array of strings List of keywords describing the collection. |
| version | string Version of the collection. This property REQUIRES to add |
| deprecated | boolean Default: false Specifies that the collection is deprecated with the potential to be removed. It should be transitioned out of usage as soon as possible and users should refrain from using it in new projects. A link with relation type This property REQUIRES to add |
| license required | string (stac_license) License(s) of the data as a SPDX License identifier.
Alternatively, use Non-SPDX licenses SHOULD add a link to the license text with the
|
Array of objects (stac_providers) A list of providers, which MAY include all organizations capturing or processing the data or the hosting provider. Providers SHOULD be listed in chronological order with the most recent provider being the last element of the list. | |
required | object (Collection Extent) The extent of the data in the collection. Additional members MAY be added to represent other extents, for example, thermal or pressure ranges. The first item in the array always describes the overall extent of the data. All subsequent items describe more preciseextents, e.g. to identify clusters of data. Clients only interested in the overall extent will only need to access the first item in each array. |
required | Array of objects (Link) Links related to this collection. Could reference to licensing information, other meta data formats with additional information or a preview image. Providing links with the following
For additional relation types see also the lists of common relation types in openEO and the STAC specification for Collections. |
required | object (STAC Collection Cube Dimensions) The named default dimensions of the data cube. Names must be unique per collection. The keys of the object are the dimension names. For interoperability, it is RECOMMENDED to use the following dimension names if there is only a single dimension with the specified criteria:
This property REQUIRES to add a version of the data cube extension to the list
of |
required | object (STAC Summaries (Collection Properties)) Collection properties from STAC extensions (e.g. EO, SAR, Satellite or Scientific) or even custom extensions. Summaries are either a unique set of all available
values, statistics or a JSON Schema. Statistics only
specify the range (minimum and maximum values) by default,
but can optionally be accompanied by additional
statistical values. The range can specify the
potential range of values, but it is recommended to be
as precise as possible. The set of values MUST contain
at least one element and it is strongly RECOMMENDED to
list all values. It is recommended to list as many
properties as reasonable so that consumers get a full
overview of the Collection. Properties that are
covered by the Collection specification (e.g.
Potential fields for the summaries can be found here:
|
object (Assets) Dictionary of asset objects for data that can be downloaded, each with a unique key. The keys MAY be used by clients as file names. |
Response samples
- 200
- 4XX
- 5XX
{- "stac_version": "1.0.0",
- "type": "Collection",
- "id": "Sentinel-2",
- "title": "Sentinel-2 MSI L2A",
- "description": "Sentinel-2A is a wide-swath, high-resolution, multi-spectral imaging mission supporting Copernicus Land Monitoring studies.",
- "license": "proprietary",
- "keywords": [
- "copernicus",
- "esa",
- "msi",
- "sentinel"
], - "providers": [
- {
- "name": "European Space Agency (ESA)",
- "roles": [
- "producer",
- "licensor"
],
}, - {
- "name": "Google",
- "roles": [
- "host"
],
}
], - "extent": {
- "spatial": {
- "bbox": [
- [
- -180,
- -56,
- 180,
- 83
]
]
}, - "temporal": {
- "interval": [
- [
- "2015-06-23T00:00:00Z",
- null
]
]
}
}, - "links": [
- {
- "rel": "license",
- "type": "application/pdf"
}, - {
- "type": "application/schema+json"
}, - {
- "rel": "about",
- "type": "text/html",
- "title": "ESA Sentinel-2 MSI Level-1C User Guide"
}, - {
- "rel": "example",
- "type": "application/json",
- "title": "Example Process for True-Color Visualization"
}, - {
- "rel": "example",
- "type": "application/json",
- "title": "Example Process for NDVI Calculation and Visualization"
}
], - "cube:dimensions": {
- "x": {
- "type": "spatial",
- "axis": "x",
- "extent": [
- -180,
- 180
], - "reference_system": 4326
}, - "y": {
- "type": "spatial",
- "axis": "y",
- "extent": [
- -56,
- 83
], - "reference_system": 4326
}, - "t": {
- "type": "temporal",
- "extent": [
- "2015-06-23T00:00:00Z",
- null
], - "step": null
}, - "bands": {
- "type": "bands",
- "values": [
- "B1",
- "B2",
- "B3",
- "B4",
- "B5",
- "B6",
- "B7",
- "B8",
- "B8A",
- "B9",
- "B10",
- "B11",
- "B12"
]
}
}, - "summaries": {
- "constellation": [
- "Sentinel-2"
], - "platform": [
- "Sentinel-2A",
- "Sentinel-2B"
], - "instruments": [
- "MSI"
], - "eo:cloud_cover": {
- "minimum": 0,
- "maximum": 75
}, - "sat:orbit_state": [
- "ascending",
- "descending"
], - "gsd": [
- 10,
- 20,
- 60
], - "eo:bands": [
- {
- "name": "B1",
- "common_name": "coastal",
- "center_wavelength": 0.4439,
- "gsd": 60
}, - {
- "name": "B2",
- "common_name": "blue",
- "center_wavelength": 0.4966,
- "gsd": 10
}, - {
- "name": "B3",
- "common_name": "green",
- "center_wavelength": 0.56,
- "gsd": 10
}, - {
- "name": "B4",
- "common_name": "red",
- "center_wavelength": 0.6645,
- "gsd": 10
}, - {
- "name": "B5",
- "center_wavelength": 0.7039,
- "gsd": 20
}, - {
- "name": "B6",
- "center_wavelength": 0.7402,
- "gsd": 20
}, - {
- "name": "B7",
- "center_wavelength": 0.7825,
- "gsd": 20
}, - {
- "name": "B8",
- "common_name": "nir",
- "center_wavelength": 0.8351,
- "gsd": 10
}, - {
- "name": "B8A",
- "common_name": "nir08",
- "center_wavelength": 0.8648,
- "gsd": 20
}, - {
- "name": "B9",
- "common_name": "nir09",
- "center_wavelength": 0.945,
- "gsd": 60
}, - {
- "name": "B10",
- "common_name": "cirrus",
- "center_wavelength": 1.3735,
- "gsd": 60
}, - {
- "name": "B11",
- "common_name": "swir16",
- "center_wavelength": 1.6137,
- "gsd": 20
}, - {
- "name": "B12",
- "common_name": "swir22",
- "center_wavelength": 2.2024,
- "gsd": 20
}
], - "proj:epsg": {
- "minimum": 32601,
- "maximum": 32660
}
}, - "assets": {
- "thumbnail": {
- "type": "image/png",
- "title": "Preview",
- "roles": [
- "thumbnail"
]
}, - "inspire": {
- "type": "application/xml",
- "title": "INSPIRE metadata",
- "description": "INSPIRE compliant XML metadata",
- "roles": [
- "metadata"
]
}
}
}Metadata filters for a specific dataset
Lists all supported metadata filters (also called "queryables") for a specific collection.
This endpoint is compatible with the endpoint defined in the STAC API extension
filter and
OGC API - Features - Part 3: Filtering.
For a precise definition please follow those specifications.
This endpoints provides a JSON Schema for each queryable that openEO users can use in multiple scenarios:
- For loading data from the collection, e.g. in the process
load_collection. - For filtering items using CQL2 on the
/collections/{collection_id}/itemsendpoint (if STAC API - Features is implemented in addition to the openEO API).
Note: Providing the Bearer token is REQUIRED for private collections.
Authorizations:
path Parameters
| collection_id required | string (collection_id) ^[\w\-\.~\/]+$ Example: Sentinel-2A Collection identifier |
Responses
Response Schema: application/schema+json
| $schema | string <uri> Default: "http://json-schema.org/draft-07/schema#" The JSON Schema version. If not given in the context of openEO,
defaults to JSON Schema draft-07: The default value for |
| $id | string <uri> ID of your JSON Schema. |
json_schema_type (string) or Array of json_schema_type (strings) The allowed data type(s) for a value. If this property is not present, all data types are allowed. | |
| pattern | string <regex> The regular expression a string value must match against. |
| enum | Array of any An exclusive list of allowed values. |
| minimum | number The minimum value (inclusive) allowed for a numerical value. |
| maximum | number The maximum value (inclusive) allowed for a numerical value. |
| minItems | number >= 0 Default: 0 The minimum number of items required in an array. |
| maxItems | number >= 0 The maximum number of items required in an array. |
Array of JSON Schema (objects) or JSON Schema (object) Specifies schemas for the items in an array. | |
| property name* additional property | any Any other property supported by the JSON Schema version that is given through the property |
Response samples
- 200
- 4XX
- 5XX
{- "type": "object",
- "title": "Sentinel-2A",
- "properties": {
- "eo:cloud_cover": {
- "title": "Cloud Cover",
- "type": "number",
- "minimum": 0,
- "maximum": 100
}, - "platform": {
- "title": "Platform",
- "description": "The satellite platform.",
- "type": "string",
- "enum": [
- "sentinel-2a",
- "sentinel-2b"
]
}
}, - "additionalProperties": false
}The process discovery endpoints provide details about the predefined processes that are available at the back-end. To list user-defined processes see 'User-Defined Processes'.
Supported predefined processes
Lists all predefined processes and returns detailed process descriptions, including parameters and return values.
Authorizations:
query Parameters
| limit | integer >= 1 Example: limit=10 This parameter enables pagination for the endpoint and specifies the maximum number of
elements that arrays in the top-level object (e.g. collections, processes, batch jobs,
secondary services, log entries, etc.) are allowed to contain.
The Pagination is OPTIONAL: back-ends or clients may not support it. Therefore, it MUST be implemented in a way that clients not supporting pagination get all resources regardless. Back-ends not supporting pagination MUST return all resources. If the response is paginated, the |
Responses
Response Schema: application/json
| version | string or null Version number of the openEO process specification this back-end targets. If not provided or |
required | Array of objects (Predefined Process) |
required | Array of objects (links_pagination) Links related to this list of resources, for example links for pagination or alternative formats such as a human-readable HTML version. The links array MUST NOT be paginated. If pagination is implemented, the following
For additional relation types see also the lists of common relation types in openEO. |
Response samples
- 200
- 4XX
- 5XX
{- "processes": [
- {
- "id": "apply",
- "summary": "Apply a process to each pixel",
- "description": "Applies a *unary* process to each pixel value in the data cube (i.e. a local operation). A unary process takes a single value and returns a single value, for example ``abs()`` or ``linear_scale_range()``.",
- "categories": [
- "cubes"
], - "parameters": [
- {
- "name": "data",
- "description": "A data cube.",
- "schema": {
- "type": "object",
- "subtype": "datacube"
}
}, - {
- "name": "process",
- "description": "A unary process to be applied on each value, may consist of multiple sub-processes.",
- "schema": {
- "type": "object",
- "subtype": "process-graph",
- "parameters": [
- {
- "name": "x",
- "description": "The value to process.",
- "schema": {
- "description": "Any data type."
}
}
]
}
}
], - "returns": {
- "description": "A data cube with the newly computed values. The resolution, cardinality and the number of dimensions are the same as for the original data cube.",
- "schema": {
- "type": "object",
- "subtype": "datacube"
}
}
}, - {
- "id": "multiply",
- "summary": "Multiplication of two numbers",
- "description": "Multiplies the two numbers `x` and `y` (*x * y*) and returns the computed product.\n\nNo-data values are taken into account so that `null` is returned if any element is such a value.\n\nThe computations follow [IEEE Standard 754](https://ieeexplore.ieee.org/document/8766229) whenever the processing environment supports it.",
- "categories": [
- "math"
], - "parameters": [
- {
- "name": "x",
- "description": "The multiplier.",
- "schema": {
- "type": [
- "number",
- "null"
]
}
}, - {
- "name": "y",
- "description": "The multiplicand.",
- "schema": {
- "type": [
- "number",
- "null"
]
}
}
], - "returns": {
- "description": "The computed product of the two numbers.",
- "schema": {
- "type": [
- "number",
- "null"
]
}
}, - "exceptions": {
- "MultiplicandMissing": {
- "message": "Multiplication requires at least two numbers."
}
}, - "examples": [
- {
- "arguments": {
- "x": 5,
- "y": 2.5
}, - "returns": 12.5
}, - {
- "arguments": {
- "x": -2,
- "y": -4
}, - "returns": 8
}, - {
- "arguments": {
- "x": 1,
- "y": null
}, - "returns": null
}
], - "links": [
- {
- "rel": "about",
- "title": "Product explained by Wolfram MathWorld"
}, - {
- "rel": "about",
- "title": "IEEE Standard 754-2019 for Floating-Point Arithmetic"
}
]
}
], - "links": [
- {
- "rel": "alternate",
- "type": "text/html",
- "title": "HTML version of the processes"
}
]
}List all user-defined processes
Lists all user-defined processes (process graphs) of the authenticated user that are stored at the back-end.
It is strongly RECOMMENDED to keep the response size small by
omitting larger optional values from the objects in processes
(e.g. the exceptions, examples and links properties).
To get the full metadata for a user-defined process clients MUST
request GET /process_graphs/{process_graph_id}.
Authorizations:
query Parameters
| limit | integer >= 1 Example: limit=10 This parameter enables pagination for the endpoint and specifies the maximum number of
elements that arrays in the top-level object (e.g. collections, processes, batch jobs,
secondary services, log entries, etc.) are allowed to contain.
The Pagination is OPTIONAL: back-ends or clients may not support it. Therefore, it MUST be implemented in a way that clients not supporting pagination get all resources regardless. Back-ends not supporting pagination MUST return all resources. If the response is paginated, the |
Responses
Response Schema: application/json
required | Array of objects (User-defined Process Metadata) Array of user-defined processes |
required | Array of objects (links_pagination) Links related to this list of resources, for example links for pagination or alternative formats such as a human-readable HTML version. The links array MUST NOT be paginated. If pagination is implemented, the following
For additional relation types see also the lists of common relation types in openEO. |
Response samples
- 200
- 4XX
- 5XX
{- "processes": [
- {
- "id": "evi",
- "summary": "Enhanced Vegetation Index",
- "description": "Computes the Enhanced Vegetation Index (EVI). It is computed with the following formula: `2.5 * (NIR - RED) / (1 + NIR + 6*RED + -7.5*BLUE)`.",
- "parameters": [
- {
- "name": "red",
- "description": "Value from the red band.",
- "schema": {
- "type": "number"
}
}, - {
- "name": "blue",
- "description": "Value from the blue band.",
- "schema": {
- "type": "number"
}
}, - {
- "name": "nir",
- "description": "Value from the near infrared band.",
- "schema": {
- "type": "number"
}
}
], - "returns": {
- "description": "Computed EVI.",
- "schema": {
- "type": "number"
}
}
}, - {
- "id": "ndsi",
- "summary": "Normalized-Difference Snow Index",
- "parameters": [
- {
- "name": "green",
- "description": "Value from the Visible Green (0.53 - 0.61 micrometers) band.",
- "schema": {
- "type": "number"
}
}, - {
- "name": "swir",
- "description": "Value from the Short Wave Infrared (1.55 - 1.75 micrometers) band.",
- "schema": {
- "type": "number"
}
}
], - "returns": {
- "schema": {
- "type": "number"
}
}
}, - {
- "id": "my_custom_process"
}
], - "links": [ ]
}Full metadata for a user-defined process
Lists all information about a user-defined process, including its process graph.
Authorizations:
path Parameters
| process_graph_id required | string (process_id) ^\w+$ Example: ndvi Per-user unique identifier for a user-defined process. |
Responses
Response Schema: application/json
| summary | string or null A short summary of what the process does. |
| description | string or null <commonmark> Detailed description to explain the entity. CommonMark 0.29 syntax MAY be used for rich text representation. In addition to the CommonMark syntax, clients can convert process IDs that are formatted as in the following example into links instead of code blocks: |
Array of objects or null (Process Parameter) A list of parameters. The order in the array corresponds to the parameter order to be used in clients that do not support named parameters. Note: Specifying an empty array is different from (if allowed)
| |
object or null (Process Return Value) Description of the data that is returned by this process. | |
| id required | string (process_id) ^\w+$ The identifier for the process. It MUST be unique across its namespace (e.g. predefined processes or user-defined processes). Clients SHOULD warn the user if a user-defined process is added with the same identifier as one of the predefined process. |
| categories | Array of strings (process_categories) A list of categories. |
| deprecated | boolean (deprecated) Default: false Declares that the specified entity is deprecated with the potential to be removed in any of the next versions. It should be transitioned out of usage as soon as possible and users should refrain from using it in new implementations. |
| experimental | boolean (experimental) Default: false Declares that the specified entity is experimental, which means that it is likely to change or may produce unpredictable behavior. Users should refrain from using it in production, but still feel encouraged to try it out and give feedback. |
object (Process Exceptions) Declares exceptions (errors) that might occur during execution of this process. This list is just for informative purposes and may be incomplete. This list MUST only contain exceptions that stop the execution of a process and MUST NOT contain warnings, notices or debugging messages. It is meant to primarily contain errors that have been caused by the user. It is RECOMMENDED that exceptions are referred to and explained in process or parameter descriptions. The keys define the error code and MUST match the following pattern:
This schema follows the schema of the general openEO error list (see errors.json). | |
Array of objects (Process Example) Examples, may be used for unit tests. | |
Array of objects (Link) Links related to this process, e.g. additional external documentation. Providing links with the following
For additional relation types see also the lists of common relation types in openEO. | |
required | object (Process Graph) A process graph defines a graph-like structure as a connected set of executable processes. Each key is a unique identifier (node ID) that is used to refer to the process in the graph. |
Response samples
- 200
- 4XX
- 5XX
A user-defined process that computes the Enhanced Vegetation Index (EVI).
{- "id": "evi",
- "summary": "Enhanced Vegetation Index",
- "description": "Computes the Enhanced Vegetation Index (EVI). It is computed with the following formula: `2.5 * (NIR - RED) / (1 + NIR + 6*RED + -7.5*BLUE)`.",
- "parameters": [
- {
- "name": "red",
- "description": "Value from the red band.",
- "schema": {
- "type": "number"
}
}, - {
- "name": "blue",
- "description": "Value from the blue band.",
- "schema": {
- "type": "number"
}
}, - {
- "name": "nir",
- "description": "Value from the near infrared band.",
- "schema": {
- "type": "number"
}
}
], - "returns": {
- "description": "Computed EVI.",
- "schema": {
- "type": "number"
}
}, - "process_graph": {
- "sub": {
- "process_id": "subtract",
- "arguments": {
- "x": {
- "from_parameter": "nir"
}, - "y": {
- "from_parameter": "red"
}
}
}, - "p1": {
- "process_id": "multiply",
- "arguments": {
- "x": 6,
- "y": {
- "from_parameter": "red"
}
}
}, - "p2": {
- "process_id": "multiply",
- "arguments": {
- "x": -7.5,
- "y": {
- "from_parameter": "blue"
}
}
}, - "sum": {
- "process_id": "sum",
- "arguments": {
- "data": [
- 1,
- {
- "from_parameter": "nir"
}, - {
- "from_node": "p1"
}, - {
- "from_node": "p2"
}
]
}
}, - "div": {
- "process_id": "divide",
- "arguments": {
- "x": {
- "from_node": "sub"
}, - "y": {
- "from_node": "sum"
}
}
}, - "p3": {
- "process_id": "multiply",
- "arguments": {
- "x": 2.5,
- "y": {
- "from_node": "div"
}
}, - "result": true
}
}
}These endpoints allow to store and manage user-defined processes with their process graphs at the back-end.
Validate a user-defined process (graph)
Validates a user-defined process without executing it. A user-defined process is
considered valid unless the errors array in the response contains at
least one error.
Checks whether the process graph is schematically correct and the processes are supported by the back-end. It MUST also check the arguments against the schema, but checking whether the arguments are adequate in the context of data is OPTIONAL. For example, a non-existing band name may get rejected only by a few back-ends. The validation MUST NOT throw an error for unresolvable process parameters.
Back-ends MUST validate the process graph. Validating the corresponding metadata is OPTIONAL.
Errors that usually occur during processing MAY NOT get reported, e.g. if a referenced file is accessible at the time of execution.
Back-ends can either report all errors at once or stop the validation once they found the first error.
Please note that a validation always returns with HTTP status code 200. Error codes in the 4xx and 5xx ranges MUST be returned only when the general validation request is invalid (e.g. server is busy or properties in the request body are missing), but never if an error was found during validation of the user-defined process (e.g. an unsupported process).
Authorizations:
Request Body schema: application/jsonrequired
Specifies the user-defined process to be validated.
| id | string or null^\w+$ The identifier for the process. It MUST be unique across its namespace (e.g. predefined processes or user-defined processes). Clients SHOULD warn the user if a user-defined process is added with the same identifier as one of the predefined process. |
| summary | string or null A short summary of what the process does. |
| description | string or null <commonmark> Detailed description to explain the entity. CommonMark 0.29 syntax MAY be used for rich text representation. In addition to the CommonMark syntax, clients can convert process IDs that are formatted as in the following example into links instead of code blocks: |
Array of objects or null (Process Parameter) A list of parameters. The order in the array corresponds to the parameter order to be used in clients that do not support named parameters. Note: Specifying an empty array is different from (if allowed)
| |
object or null (Process Return Value) Description of the data that is returned by this process. | |
| categories | Array of strings (process_categories) A list of categories. |
| deprecated | boolean (deprecated) Default: false Declares that the specified entity is deprecated with the potential to be removed in any of the next versions. It should be transitioned out of usage as soon as possible and users should refrain from using it in new implementations. |
| experimental | boolean (experimental) Default: false Declares that the specified entity is experimental, which means that it is likely to change or may produce unpredictable behavior. Users should refrain from using it in production, but still feel encouraged to try it out and give feedback. |
object (Process Exceptions) Declares exceptions (errors) that might occur during execution of this process. This list is just for informative purposes and may be incomplete. This list MUST only contain exceptions that stop the execution of a process and MUST NOT contain warnings, notices or debugging messages. It is meant to primarily contain errors that have been caused by the user. It is RECOMMENDED that exceptions are referred to and explained in process or parameter descriptions. The keys define the error code and MUST match the following pattern:
This schema follows the schema of the general openEO error list (see errors.json). | |
Array of objects (Process Example) Examples, may be used for unit tests. | |
Array of objects (Link) Links related to this process, e.g. additional external documentation. Providing links with the following
For additional relation types see also the lists of common relation types in openEO. | |
required | object (Process Graph) A process graph defines a graph-like structure as a connected set of executable processes. Each key is a unique identifier (node ID) that is used to refer to the process in the graph. |
Responses
Response Schema: application/json
required | Array of objects (General Error) A list of validation errors. |
Request samples
- Payload
A user-defined process that computes the Enhanced Vegetation Index (EVI).
{- "id": "evi",
- "summary": "Enhanced Vegetation Index",
- "description": "Computes the Enhanced Vegetation Index (EVI). It is computed with the following formula: `2.5 * (NIR - RED) / (1 + NIR + 6*RED + -7.5*BLUE)`.",
- "parameters": [
- {
- "name": "red",
- "description": "Value from the red band.",
- "schema": {
- "type": "number"
}
}, - {
- "name": "blue",
- "description": "Value from the blue band.",
- "schema": {
- "type": "number"
}
}, - {
- "name": "nir",
- "description": "Value from the near infrared band.",
- "schema": {
- "type": "number"
}
}
], - "returns": {
- "description": "Computed EVI.",
- "schema": {
- "type": "number"
}
}, - "process_graph": {
- "sub": {
- "process_id": "subtract",
- "arguments": {
- "x": {
- "from_parameter": "nir"
}, - "y": {
- "from_parameter": "red"
}
}
}, - "p1": {
- "process_id": "multiply",
- "arguments": {
- "x": 6,
- "y": {
- "from_parameter": "red"
}
}
}, - "p2": {
- "process_id": "multiply",
- "arguments": {
- "x": -7.5,
- "y": {
- "from_parameter": "blue"
}
}
}, - "sum": {
- "process_id": "sum",
- "arguments": {
- "data": [
- 1,
- {
- "from_parameter": "nir"
}, - {
- "from_node": "p1"
}, - {
- "from_node": "p2"
}
]
}
}, - "div": {
- "process_id": "divide",
- "arguments": {
- "x": {
- "from_node": "sub"
}, - "y": {
- "from_node": "sum"
}
}
}, - "p3": {
- "process_id": "multiply",
- "arguments": {
- "x": 2.5,
- "y": {
- "from_node": "div"
}
}, - "result": true
}
}
}Response samples
- 200
- 4XX
- 5XX
{- "errors": [
- {
- "id": "550e8400-e29b-11d4-a716-446655440000",
- "code": "SampleError",
- "message": "Parameter 'sample' is missing.",
}
]
}List all user-defined processes
Lists all user-defined processes (process graphs) of the authenticated user that are stored at the back-end.
It is strongly RECOMMENDED to keep the response size small by
omitting larger optional values from the objects in processes
(e.g. the exceptions, examples and links properties).
To get the full metadata for a user-defined process clients MUST
request GET /process_graphs/{process_graph_id}.
Authorizations:
query Parameters
| limit | integer >= 1 Example: limit=10 This parameter enables pagination for the endpoint and specifies the maximum number of
elements that arrays in the top-level object (e.g. collections, processes, batch jobs,
secondary services, log entries, etc.) are allowed to contain.
The Pagination is OPTIONAL: back-ends or clients may not support it. Therefore, it MUST be implemented in a way that clients not supporting pagination get all resources regardless. Back-ends not supporting pagination MUST return all resources. If the response is paginated, the |
Responses
Response Schema: application/json
required | Array of objects (User-defined Process Metadata) Array of user-defined processes |
required | Array of objects (links_pagination) Links related to this list of resources, for example links for pagination or alternative formats such as a human-readable HTML version. The links array MUST NOT be paginated. If pagination is implemented, the following
For additional relation types see also the lists of common relation types in openEO. |
Response samples
- 200
- 4XX
- 5XX
{- "processes": [
- {
- "id": "evi",
- "summary": "Enhanced Vegetation Index",
- "description": "Computes the Enhanced Vegetation Index (EVI). It is computed with the following formula: `2.5 * (NIR - RED) / (1 + NIR + 6*RED + -7.5*BLUE)`.",
- "parameters": [
- {
- "name": "red",
- "description": "Value from the red band.",
- "schema": {
- "type": "number"
}
}, - {
- "name": "blue",
- "description": "Value from the blue band.",
- "schema": {
- "type": "number"
}
}, - {
- "name": "nir",
- "description": "Value from the near infrared band.",
- "schema": {
- "type": "number"
}
}
], - "returns": {
- "description": "Computed EVI.",
- "schema": {
- "type": "number"
}
}
}, - {
- "id": "ndsi",
- "summary": "Normalized-Difference Snow Index",
- "parameters": [
- {
- "name": "green",
- "description": "Value from the Visible Green (0.53 - 0.61 micrometers) band.",
- "schema": {
- "type": "number"
}
}, - {
- "name": "swir",
- "description": "Value from the Short Wave Infrared (1.55 - 1.75 micrometers) band.",
- "schema": {
- "type": "number"
}
}
], - "returns": {
- "schema": {
- "type": "number"
}
}
}, - {
- "id": "my_custom_process"
}
], - "links": [ ]
}Full metadata for a user-defined process
Lists all information about a user-defined process, including its process graph.
Authorizations:
path Parameters
| process_graph_id required | string (process_id) ^\w+$ Example: ndvi Per-user unique identifier for a user-defined process. |
Responses
Response Schema: application/json
| summary | string or null A short summary of what the process does. |
| description | string or null <commonmark> Detailed description to explain the entity. CommonMark 0.29 syntax MAY be used for rich text representation. In addition to the CommonMark syntax, clients can convert process IDs that are formatted as in the following example into links instead of code blocks: |
Array of objects or null (Process Parameter) A list of parameters. The order in the array corresponds to the parameter order to be used in clients that do not support named parameters. Note: Specifying an empty array is different from (if allowed)
| |
object or null (Process Return Value) Description of the data that is returned by this process. | |
| id required | string (process_id) ^\w+$ The identifier for the process. It MUST be unique across its namespace (e.g. predefined processes or user-defined processes). Clients SHOULD warn the user if a user-defined process is added with the same identifier as one of the predefined process. |
| categories | Array of strings (process_categories) A list of categories. |
| deprecated | boolean (deprecated) Default: false Declares that the specified entity is deprecated with the potential to be removed in any of the next versions. It should be transitioned out of usage as soon as possible and users should refrain from using it in new implementations. |
| experimental | boolean (experimental) Default: false Declares that the specified entity is experimental, which means that it is likely to change or may produce unpredictable behavior. Users should refrain from using it in production, but still feel encouraged to try it out and give feedback. |
object (Process Exceptions) Declares exceptions (errors) that might occur during execution of this process. This list is just for informative purposes and may be incomplete. This list MUST only contain exceptions that stop the execution of a process and MUST NOT contain warnings, notices or debugging messages. It is meant to primarily contain errors that have been caused by the user. It is RECOMMENDED that exceptions are referred to and explained in process or parameter descriptions. The keys define the error code and MUST match the following pattern:
This schema follows the schema of the general openEO error list (see errors.json). | |
Array of objects (Process Example) Examples, may be used for unit tests. | |
Array of objects (Link) Links related to this process, e.g. additional external documentation. Providing links with the following
For additional relation types see also the lists of common relation types in openEO. | |
required | object (Process Graph) A process graph defines a graph-like structure as a connected set of executable processes. Each key is a unique identifier (node ID) that is used to refer to the process in the graph. |
Response samples
- 200
- 4XX
- 5XX
A user-defined process that computes the Enhanced Vegetation Index (EVI).
{- "id": "evi",
- "summary": "Enhanced Vegetation Index",
- "description": "Computes the Enhanced Vegetation Index (EVI). It is computed with the following formula: `2.5 * (NIR - RED) / (1 + NIR + 6*RED + -7.5*BLUE)`.",
- "parameters": [
- {
- "name": "red",
- "description": "Value from the red band.",
- "schema": {
- "type": "number"
}
}, - {
- "name": "blue",
- "description": "Value from the blue band.",
- "schema": {
- "type": "number"
}
}, - {
- "name": "nir",
- "description": "Value from the near infrared band.",
- "schema": {
- "type": "number"
}
}
], - "returns": {
- "description": "Computed EVI.",
- "schema": {
- "type": "number"
}
}, - "process_graph": {
- "sub": {
- "process_id": "subtract",
- "arguments": {
- "x": {
- "from_parameter": "nir"
}, - "y": {
- "from_parameter": "red"
}
}
}, - "p1": {
- "process_id": "multiply",
- "arguments": {
- "x": 6,
- "y": {
- "from_parameter": "red"
}
}
}, - "p2": {
- "process_id": "multiply",
- "arguments": {
- "x": -7.5,
- "y": {
- "from_parameter": "blue"
}
}
}, - "sum": {
- "process_id": "sum",
- "arguments": {
- "data": [
- 1,
- {
- "from_parameter": "nir"
}, - {
- "from_node": "p1"
}, - {
- "from_node": "p2"
}
]
}
}, - "div": {
- "process_id": "divide",
- "arguments": {
- "x": {
- "from_node": "sub"
}, - "y": {
- "from_node": "sum"
}
}
}, - "p3": {
- "process_id": "multiply",
- "arguments": {
- "x": 2.5,
- "y": {
- "from_node": "div"
}
}, - "result": true
}
}
}Store a user-defined process
Stores a provided user-defined process with process graph that can be reused in other processes.
If a process with the specified process_graph_id exists, the process
is fully replaced. The id can not be changed for existing user-defined
processes. The id MUST be unique across its namespace.
Partially updating user-defined processes is not supported.
To simplify exchanging user-defined processes, the property id can be part of
the request body. If the values do not match, the value for id gets
replaced with the value from the process_graph_id parameter in the
path.
Authorizations:
path Parameters
| process_graph_id required | string (process_id) ^\w+$ Example: ndvi Per-user unique identifier for a user-defined process. |
Request Body schema: application/jsonrequired
Specifies the process graph with its meta data.
| id | string or null^\w+$ The identifier for the process. It MUST be unique across its namespace (e.g. predefined processes or user-defined processes). Clients SHOULD warn the user if a user-defined process is added with the same identifier as one of the predefined process. |
| summary | string or null A short summary of what the process does. |
| description | string or null <commonmark> Detailed description to explain the entity. CommonMark 0.29 syntax MAY be used for rich text representation. In addition to the CommonMark syntax, clients can convert process IDs that are formatted as in the following example into links instead of code blocks: |
Array of objects or null (Process Parameter) A list of parameters. The order in the array corresponds to the parameter order to be used in clients that do not support named parameters. Note: Specifying an empty array is different from (if allowed)
| |
object or null (Process Return Value) Description of the data that is returned by this process. | |
| categories | Array of strings (process_categories) A list of categories. |
| deprecated | boolean (deprecated) Default: false Declares that the specified entity is deprecated with the potential to be removed in any of the next versions. It should be transitioned out of usage as soon as possible and users should refrain from using it in new implementations. |
| experimental | boolean (experimental) Default: false Declares that the specified entity is experimental, which means that it is likely to change or may produce unpredictable behavior. Users should refrain from using it in production, but still feel encouraged to try it out and give feedback. |
object (Process Exceptions) Declares exceptions (errors) that might occur during execution of this process. This list is just for informative purposes and may be incomplete. This list MUST only contain exceptions that stop the execution of a process and MUST NOT contain warnings, notices or debugging messages. It is meant to primarily contain errors that have been caused by the user. It is RECOMMENDED that exceptions are referred to and explained in process or parameter descriptions. The keys define the error code and MUST match the following pattern:
This schema follows the schema of the general openEO error list (see errors.json). | |
Array of objects (Process Example) Examples, may be used for unit tests. | |
Array of objects (Link) Links related to this process, e.g. additional external documentation. Providing links with the following
For additional relation types see also the lists of common relation types in openEO. | |
required | object (Process Graph) A process graph defines a graph-like structure as a connected set of executable processes. Each key is a unique identifier (node ID) that is used to refer to the process in the graph. |
Responses
Request samples
- Payload
A user-defined process that computes the Enhanced Vegetation Index (EVI).
{- "id": "evi",
- "summary": "Enhanced Vegetation Index",
- "description": "Computes the Enhanced Vegetation Index (EVI). It is computed with the following formula: `2.5 * (NIR - RED) / (1 + NIR + 6*RED + -7.5*BLUE)`.",
- "parameters": [
- {
- "name": "red",
- "description": "Value from the red band.",
- "schema": {
- "type": "number"
}
}, - {
- "name": "blue",
- "description": "Value from the blue band.",
- "schema": {
- "type": "number"
}
}, - {
- "name": "nir",
- "description": "Value from the near infrared band.",
- "schema": {
- "type": "number"
}
}
], - "returns": {
- "description": "Computed EVI.",
- "schema": {
- "type": "number"
}
}, - "process_graph": {
- "sub": {
- "process_id": "subtract",
- "arguments": {
- "x": {
- "from_parameter": "nir"
}, - "y": {
- "from_parameter": "red"
}
}
}, - "p1": {
- "process_id": "multiply",
- "arguments": {
- "x": 6,
- "y": {
- "from_parameter": "red"
}
}
}, - "p2": {
- "process_id": "multiply",
- "arguments": {
- "x": -7.5,
- "y": {
- "from_parameter": "blue"
}
}
}, - "sum": {
- "process_id": "sum",
- "arguments": {
- "data": [
- 1,
- {
- "from_parameter": "nir"
}, - {
- "from_node": "p1"
}, - {
- "from_node": "p2"
}
]
}
}, - "div": {
- "process_id": "divide",
- "arguments": {
- "x": {
- "from_node": "sub"
}, - "y": {
- "from_node": "sum"
}
}
}, - "p3": {
- "process_id": "multiply",
- "arguments": {
- "x": 2.5,
- "y": {
- "from_node": "div"
}
}, - "result": true
}
}
}Response samples
- 4XX
- 5XX
{- "id": "550e8400-e29b-11d4-a716-446655440000",
- "code": "SampleError",
- "message": "Parameter 'sample' is missing.",
}Delete a user-defined process
Deletes the data related to this user-defined process, including its process graph.
Does NOT delete jobs or services that reference this user-defined process.
Authorizations:
path Parameters
| process_graph_id required | string (process_id) ^\w+$ Example: ndvi Per-user unique identifier for a user-defined process. |
Responses
Response samples
- 4XX
- 5XX
{- "id": "550e8400-e29b-11d4-a716-446655440000",
- "code": "SampleError",
- "message": "Parameter 'sample' is missing.",
}Organizes and manages data processing on the back-end, either as synchronous on-demand computation or batch jobs.
Supported file formats
Lists supported input and output file formats. Input file formats specify which file a back-end can read from. Output file formats specify which file a back-end can write to.
The response to this request is an object listing all available input and output file formats separately with their parameters and additional data. This endpoint does not include the supported secondary web services.
Note: Format names and parameters MUST be fully aligned with the GDAL codes if available, see GDAL Raster Formats and OGR Vector Formats. It is OPTIONAL to support all output format parameters supported by GDAL. Some file formats not available through GDAL may be defined centrally for openEO. Custom file formats or parameters MAY be defined.
The format descriptions MUST describe how the file formats relate to data cubes. Input file formats MUST describe how the files have to be structured to be transformed into data cubes. Output file formats MUST describe how the data cubes are stored at the back-end and how the resulting file structure looks like.
Back-ends MUST NOT support aliases, for example it is not allowed to
support geotiff instead of gtiff. Nevertheless, openEO Clients MAY
translate user input for convenience (e.g. translate geotiff to
gtiff). Also, for a better user experience the back-end can specify a
title.
Format names MUST be accepted in a case insensitive manner throughout the API.
Authorizations:
Responses
Response Schema: application/json
required | object (Input File Formats) Map of supported input file formats, i.e. file formats a back-end can read from. The property keys are the file format names that are used by clients and users, for example in process graphs. |
required | object (Output File Formats) Map of supported output file formats, i.e. file formats a back-end can write to. The property keys are the file format names that are used by clients and users, for example in process graphs. |
Response samples
- 200
- 4XX
- 5XX
{- "output": {
- "GTiff": {
- "title": "GeoTiff",
- "description": "Export to GeoTiff. Does not support cloud-optimized GeoTiffs (COGs) yet.",
- "gis_data_types": [
- "raster"
], - "parameters": {
- "tiled": {
- "type": "boolean",
- "description": "This option can be used to force creation of tiled TIFF files [true]. By default [false] stripped TIFF files are created.",
- "default": false
}, - "compress": {
- "type": "string",
- "description": "Set the compression to use.",
- "default": "NONE",
- "enum": [
- "JPEG",
- "LZW",
- "DEFLATE",
- "NONE"
]
}, - "jpeg_quality": {
- "type": "integer",
- "description": "Set the JPEG quality when using JPEG.",
- "minimum": 1,
- "maximum": 100,
- "default": 75
}
}, - "links": [
- {
- "rel": "about",
- "title": "GDAL on the GeoTiff file format and storage options"
}
]
}, - "GPKG": {
- "title": "OGC GeoPackage",
- "gis_data_types": [
- "raster",
- "vector"
], - "parameters": {
- "version": {
- "type": "string",
- "description": "Set GeoPackage version. In AUTO mode, this will be equivalent to 1.2 starting with GDAL 2.3.",
- "enum": [
- "auto",
- "1",
- "1.1",
- "1.2"
], - "default": "auto"
}
}, - "links": [
- {
- "rel": "about",
- "title": "GDAL on GeoPackage for raster data"
}, - {
- "rel": "about",
- "title": "GDAL on GeoPackage for vector data"
}
]
}
}, - "input": {
- "GPKG": {
- "title": "OGC GeoPackage",
- "gis_data_types": [
- "raster",
- "vector"
], - "parameters": {
- "table": {
- "type": "string",
- "description": "**RASTER ONLY.** Name of the table containing the tiles. If the GeoPackage dataset only contains one table, this option is not necessary. Otherwise, it is required."
}
}, - "links": [
- {
- "rel": "about",
- "title": "GDAL on GeoPackage for raster data"
}, - {
- "rel": "about",
- "title": "GDAL on GeoPackage for vector data"
}
]
}
}
}Validate a user-defined process (graph)
Validates a user-defined process without executing it. A user-defined process is
considered valid unless the errors array in the response contains at
least one error.
Checks whether the process graph is schematically correct and the processes are supported by the back-end. It MUST also check the arguments against the schema, but checking whether the arguments are adequate in the context of data is OPTIONAL. For example, a non-existing band name may get rejected only by a few back-ends. The validation MUST NOT throw an error for unresolvable process parameters.
Back-ends MUST validate the process graph. Validating the corresponding metadata is OPTIONAL.
Errors that usually occur during processing MAY NOT get reported, e.g. if a referenced file is accessible at the time of execution.
Back-ends can either report all errors at once or stop the validation once they found the first error.
Please note that a validation always returns with HTTP status code 200. Error codes in the 4xx and 5xx ranges MUST be returned only when the general validation request is invalid (e.g. server is busy or properties in the request body are missing), but never if an error was found during validation of the user-defined process (e.g. an unsupported process).
Authorizations:
Request Body schema: application/jsonrequired
Specifies the user-defined process to be validated.
| id | string or null^\w+$ The identifier for the process. It MUST be unique across its namespace (e.g. predefined processes or user-defined processes). Clients SHOULD warn the user if a user-defined process is added with the same identifier as one of the predefined process. |
| summary | string or null A short summary of what the process does. |
| description | string or null <commonmark> Detailed description to explain the entity. CommonMark 0.29 syntax MAY be used for rich text representation. In addition to the CommonMark syntax, clients can convert process IDs that are formatted as in the following example into links instead of code blocks: |
Array of objects or null (Process Parameter) A list of parameters. The order in the array corresponds to the parameter order to be used in clients that do not support named parameters. Note: Specifying an empty array is different from (if allowed)
| |
object or null (Process Return Value) Description of the data that is returned by this process. | |
| categories | Array of strings (process_categories) A list of categories. |
| deprecated | boolean (deprecated) Default: false Declares that the specified entity is deprecated with the potential to be removed in any of the next versions. It should be transitioned out of usage as soon as possible and users should refrain from using it in new implementations. |
| experimental | boolean (experimental) Default: false Declares that the specified entity is experimental, which means that it is likely to change or may produce unpredictable behavior. Users should refrain from using it in production, but still feel encouraged to try it out and give feedback. |
object (Process Exceptions) Declares exceptions (errors) that might occur during execution of this process. This list is just for informative purposes and may be incomplete. This list MUST only contain exceptions that stop the execution of a process and MUST NOT contain warnings, notices or debugging messages. It is meant to primarily contain errors that have been caused by the user. It is RECOMMENDED that exceptions are referred to and explained in process or parameter descriptions. The keys define the error code and MUST match the following pattern:
This schema follows the schema of the general openEO error list (see errors.json). | |
Array of objects (Process Example) Examples, may be used for unit tests. | |
Array of objects (Link) Links related to this process, e.g. additional external documentation. Providing links with the following
For additional relation types see also the lists of common relation types in openEO. | |
required | object (Process Graph) A process graph defines a graph-like structure as a connected set of executable processes. Each key is a unique identifier (node ID) that is used to refer to the process in the graph. |
Responses
Response Schema: application/json
required | Array of objects (General Error) A list of validation errors. |
Request samples
- Payload
A user-defined process that computes the Enhanced Vegetation Index (EVI).
{- "id": "evi",
- "summary": "Enhanced Vegetation Index",
- "description": "Computes the Enhanced Vegetation Index (EVI). It is computed with the following formula: `2.5 * (NIR - RED) / (1 + NIR + 6*RED + -7.5*BLUE)`.",
- "parameters": [
- {
- "name": "red",
- "description": "Value from the red band.",
- "schema": {
- "type": "number"
}
}, - {
- "name": "blue",
- "description": "Value from the blue band.",
- "schema": {
- "type": "number"
}
}, - {
- "name": "nir",
- "description": "Value from the near infrared band.",
- "schema": {
- "type": "number"
}
}
], - "returns": {
- "description": "Computed EVI.",
- "schema": {
- "type": "number"
}
}, - "process_graph": {
- "sub": {
- "process_id": "subtract",
- "arguments": {
- "x": {
- "from_parameter": "nir"
}, - "y": {
- "from_parameter": "red"
}
}
}, - "p1": {
- "process_id": "multiply",
- "arguments": {
- "x": 6,
- "y": {
- "from_parameter": "red"
}
}
}, - "p2": {
- "process_id": "multiply",
- "arguments": {
- "x": -7.5,
- "y": {
- "from_parameter": "blue"
}
}
}, - "sum": {
- "process_id": "sum",
- "arguments": {
- "data": [
- 1,
- {
- "from_parameter": "nir"
}, - {
- "from_node": "p1"
}, - {
- "from_node": "p2"
}
]
}
}, - "div": {
- "process_id": "divide",
- "arguments": {
- "x": {
- "from_node": "sub"
}, - "y": {
- "from_node": "sum"
}
}
}, - "p3": {
- "process_id": "multiply",
- "arguments": {
- "x": 2.5,
- "y": {
- "from_node": "div"
}
}, - "result": true
}
}
}Response samples
- 200
- 4XX
- 5XX
{- "errors": [
- {
- "id": "550e8400-e29b-11d4-a716-446655440000",
- "code": "SampleError",
- "message": "Parameter 'sample' is missing.",
}
]
}Process and download data synchronously
Executes a user-defined process directly (synchronously) and the result will be downloaded in the format specified in the process graph. This endpoint can be used to generate small previews or test user-defined processes before starting a batch job.
Timeouts on either client-side or server-side are to be expected for complex computations. Back-ends MAY send the openEO error ProcessGraphComplexity immediately if the computation is expected to time out. Otherwise requests MAY time-out after a certain amount of time by sending openEO error RequestTimeout.
A header named OpenEO-Costs MAY be sent with all responses, which MUST include the costs for processing and downloading the data. Additionally, a link to a log file MAY be sent in the header.
Authorizations:
Request Body schema: application/jsonrequired
Specifies the job details, e.g. the user-defined process and billing details.
required | object (Process Graph with metadata) A process graph, optionally enriched with process metadata. |
| budget | number or null (budget) >= 0 Default: null Maximum amount of costs the request is allowed to produce.
The value MUST be specified in the currency of the back-end.
No limits apply, if the value is |
| plan | string or null (billing_plan_null_default) Default: null The billing plan to process and charge the job or service with. Billing plans MUST be accepted in a case insensitive manner. Back-ends MUST resolve the billing plan in the following way:
The resolved plan MUST be persisted permanently, regardless of any
changes to the exposed billing plans in Billing plans not on the list of available plans MUST be rejected with
openEO error |
| log_level | string (min_log_level_default) Default: "info" Enum: "error" "warning" "info" "debug" The minimum severity level for log entries that the back-end stores for the processing request. The order of the levels is as follows (from low to high severity): The default minimum log level is |
| property name* additional property | any Aditional back-end specific properties are allowed. |
Responses
| Content-Type | string The appropriate media (MIME) type for the requested output format MUST be sent, if the response contains a single file. To send multiple files at once it is RECOMMENDED to use the
To mimic the results of batch jobs, it is RECOMMENDED that
|
| OpenEO-Costs | number or null (money) >= 0 Default: null Example: "12.98" MAY include the costs for processing and downloading the data. |
| OpenEO-Identifier | string^[\w\-\.~]+$ Example: "a3cca2b2aa1e3b5b" Optionally, an identifier associated with the synchronous processing request. |
| Link | string^<[^>]+>;\s?rel="monitor" Example: "<https://openeo.example/api/v1/logs/258489231>; rel=\"monitor\"" The header MAY indicate a link to a log file generated by the request. If provided, the link MUST be serialized according to RFC 8288 and MUST use the relation type |
Request samples
- Payload
{- "process": {
- "id": "ndvi",
- "summary": "string",
- "description": "string",
- "parameters": [
- {
- "schema": {
- "subtype": "string",
- "deprecated": false,
- "type": "string",
- "enum": [
- "a",
- "b"
]
}, - "name": "string",
- "description": "string",
- "optional": false,
- "deprecated": false,
- "experimental": false,
- "default": null
}
], - "returns": {
- "description": "string",
- "schema": {
- "subtype": "string",
- "deprecated": false,
- "type": "string",
- "enum": [
- "a",
- "b"
]
}
}, - "categories": [
- "string"
], - "deprecated": false,
- "experimental": false,
- "exceptions": {
- "Error Code1": {
- "description": "string",
- "message": "The value specified for the process argument '{argument}' in process '{process}' is invalid: {reason}",
- "http": 400
}, - "Error Code2": {
- "description": "string",
- "message": "The value specified for the process argument '{argument}' in process '{process}' is invalid: {reason}",
- "http": 400
}
}, - "examples": [
- {
- "title": "string",
- "description": "string",
- "arguments": {
- "property1": {
- "from_parameter": null,
- "from_node": null,
- "process_graph": null
}, - "property2": {
- "from_parameter": null,
- "from_node": null,
- "process_graph": null
}
}, - "returns": null
}
], - "links": [
], - "process_graph": {
- "dc": {
- "process_id": "load_collection",
- "arguments": {
- "id": "Sentinel-2",
- "spatial_extent": {
- "west": 16.1,
- "east": 16.6,
- "north": 48.6,
- "south": 47.2
}, - "temporal_extent": [
- "2018-01-01",
- "2018-02-01"
]
}
}, - "bands": {
- "process_id": "filter_bands",
- "description": "Filter and order the bands. The order is important for the following reduce operation.",
- "arguments": {
- "data": {
- "from_node": "dc"
}, - "bands": [
- "B08",
- "B04",
- "B02"
]
}
}, - "evi": {
- "process_id": "reduce",
- "description": "Compute the EVI. Formula: 2.5 * (NIR - RED) / (1 + NIR + 6*RED + -7.5*BLUE)",
- "arguments": {
- "data": {
- "from_node": "bands"
}, - "dimension": "bands",
- "reducer": {
- "process_graph": {
- "nir": {
- "process_id": "array_element",
- "arguments": {
- "data": {
- "from_parameter": "data"
}, - "index": 0
}
}, - "red": {
- "process_id": "array_element",
- "arguments": {
- "data": {
- "from_parameter": "data"
}, - "index": 1
}
}, - "blue": {
- "process_id": "array_element",
- "arguments": {
- "data": {
- "from_parameter": "data"
}, - "index": 2
}
}, - "sub": {
- "process_id": "subtract",
- "arguments": {
- "data": [
- {
- "from_node": "nir"
}, - {
- "from_node": "red"
}
]
}
}, - "p1": {
- "process_id": "product",
- "arguments": {
- "data": [
- 6,
- {
- "from_node": "red"
}
]
}
}, - "p2": {
- "process_id": "product",
- "arguments": {
- "data": [
- -7.5,
- {
- "from_node": "blue"
}
]
}
}, - "sum": {
- "process_id": "sum",
- "arguments": {
- "data": [
- 1,
- {
- "from_node": "nir"
}, - {
- "from_node": "p1"
}, - {
- "from_node": "p2"
}
]
}
}, - "div": {
- "process_id": "divide",
- "arguments": {
- "data": [
- {
- "from_node": "sub"
}, - {
- "from_node": "sum"
}
]
}
}, - "p3": {
- "process_id": "product",
- "arguments": {
- "data": [
- 2.5,
- {
- "from_node": "div"
}
]
}, - "result": true
}
}
}
}
}, - "mintime": {
- "process_id": "reduce",
- "description": "Compute a minimum time composite by reducing the temporal dimension",
- "arguments": {
- "data": {
- "from_node": "evi"
}, - "dimension": "temporal",
- "reducer": {
- "process_graph": {
- "min": {
- "process_id": "min",
- "arguments": {
- "data": {
- "from_parameter": "data"
}
}, - "result": true
}
}
}
}
}, - "save": {
- "process_id": "save_result",
- "arguments": {
- "data": {
- "from_node": "mintime"
}, - "format": "GTiff"
}, - "result": true
}
}
}, - "budget": 100,
- "plan": "free",
- "log_level": "warning",
- "property1": null,
- "property2": null
}Response samples
- 4XX
- 5XX
{- "id": "550e8400-e29b-11d4-a716-446655440000",
- "code": "SampleError",
- "message": "Parameter 'sample' is missing.",
}List all batch jobs
Lists all batch jobs submitted by a user.
It is strongly RECOMMENDED to keep the response size small by
omitting all optional non-scalar values (i.e. arrays and objects) from
objects in jobs (i.e. the process property).
To get the full metadata for a job clients MUST request GET /jobs/{job_id}.
Authorizations:
query Parameters
| limit | integer >= 1 Example: limit=10 This parameter enables pagination for the endpoint and specifies the maximum number of
elements that arrays in the top-level object (e.g. collections, processes, batch jobs,
secondary services, log entries, etc.) are allowed to contain.
The Pagination is OPTIONAL: back-ends or clients may not support it. Therefore, it MUST be implemented in a way that clients not supporting pagination get all resources regardless. Back-ends not supporting pagination MUST return all resources. If the response is paginated, the |
Responses
Response Schema: application/json
required | Array of objects (Batch Job) |
required | Array of objects (links_pagination) Links related to this list of resources, for example links for pagination or alternative formats such as a human-readable HTML version. The links array MUST NOT be paginated. If pagination is implemented, the following
For additional relation types see also the lists of common relation types in openEO. |
Response samples
- 200
- 4XX
- 5XX
{- "jobs": [
- {
- "id": "a3cca2b2aa1e3b5b",
- "title": "NDVI based on Sentinel-2",
- "description": "Deriving minimum NDVI measurements over pixel time series of Sentinel-2",
- "process": {
- "id": "ndvi",
- "summary": "string",
- "description": "string",
- "parameters": [
- {
- "schema": {
- "subtype": "string",
- "deprecated": false,
- "type": "string",
- "enum": [
- "a",
- "b"
]
}, - "name": "string",
- "description": "string",
- "optional": false,
- "deprecated": false,
- "experimental": false,
- "default": null
}
], - "returns": {
- "description": "string",
- "schema": {
- "subtype": "string",
- "deprecated": false,
- "type": "string",
- "enum": [
- "a",
- "b"
]
}
}, - "categories": [
- "string"
], - "deprecated": false,
- "experimental": false,
- "exceptions": {
- "Error Code1": {
- "description": "string",
- "message": "The value specified for the process argument '{argument}' in process '{process}' is invalid: {reason}",
- "http": 400
}, - "Error Code2": {
- "description": "string",
- "message": "The value specified for the process argument '{argument}' in process '{process}' is invalid: {reason}",
- "http": 400
}
}, - "examples": [
- {
- "title": "string",
- "description": "string",
- "arguments": {
- "property1": {
- "from_parameter": null,
- "from_node": null,
- "process_graph": null
}, - "property2": {
- "from_parameter": null,
- "from_node": null,
- "process_graph": null
}
}, - "returns": null
}
], - "links": [
], - "process_graph": {
- "dc": {
- "process_id": "load_collection",
- "arguments": {
- "id": "Sentinel-2",
- "spatial_extent": {
- "west": 16.1,
- "east": 16.6,
- "north": 48.6,
- "south": 47.2
}, - "temporal_extent": [
- "2018-01-01",
- "2018-02-01"
]
}
}, - "bands": {
- "process_id": "filter_bands",
- "description": "Filter and order the bands. The order is important for the following reduce operation.",
- "arguments": {
- "data": {
- "from_node": "dc"
}, - "bands": [
- "B08",
- "B04",
- "B02"
]
}
}, - "evi": {
- "process_id": "reduce",
- "description": "Compute the EVI. Formula: 2.5 * (NIR - RED) / (1 + NIR + 6*RED + -7.5*BLUE)",
- "arguments": {
- "data": {
- "from_node": "bands"
}, - "dimension": "bands",
- "reducer": {
- "process_graph": {
- "nir": {
- "process_id": "array_element",
- "arguments": {
- "data": {
- "from_parameter": "data"
}, - "index": 0
}
}, - "red": {
- "process_id": "array_element",
- "arguments": {
- "data": {
- "from_parameter": "data"
}, - "index": 1
}
}, - "blue": {
- "process_id": "array_element",
- "arguments": {
- "data": {
- "from_parameter": "data"
}, - "index": 2
}
}, - "sub": {
- "process_id": "subtract",
- "arguments": {
- "data": [
- {
- "from_node": "nir"
}, - {
- "from_node": "red"
}
]
}
}, - "p1": {
- "process_id": "product",
- "arguments": {
- "data": [
- 6,
- {
- "from_node": "red"
}
]
}
}, - "p2": {
- "process_id": "product",
- "arguments": {
- "data": [
- -7.5,
- {
- "from_node": "blue"
}
]
}
}, - "sum": {
- "process_id": "sum",
- "arguments": {
- "data": [
- 1,
- {
- "from_node": "nir"
}, - {
- "from_node": "p1"
}, - {
- "from_node": "p2"
}
]
}
}, - "div": {
- "process_id": "divide",
- "arguments": {
- "data": [
- {
- "from_node": "sub"
}, - {
- "from_node": "sum"
}
]
}
}, - "p3": {
- "process_id": "product",
- "arguments": {
- "data": [
- 2.5,
- {
- "from_node": "div"
}
]
}, - "result": true
}
}
}
}
}, - "mintime": {
- "process_id": "reduce",
- "description": "Compute a minimum time composite by reducing the temporal dimension",
- "arguments": {
- "data": {
- "from_node": "evi"
}, - "dimension": "temporal",
- "reducer": {
- "process_graph": {
- "min": {
- "process_id": "min",
- "arguments": {
- "data": {
- "from_parameter": "data"
}
}, - "result": true
}
}
}
}
}, - "save": {
- "process_id": "save_result",
- "arguments": {
- "data": {
- "from_node": "mintime"
}, - "format": "GTiff"
}, - "result": true
}
}
}, - "status": "running",
- "progress": 75.5,
- "created": "2017-01-01T09:32:12Z",
- "updated": "2017-01-01T09:54:18Z",
- "queued": "2017-01-01T09:34:00Z",
- "started": "2017-01-01T09:36:18Z",
- "unpublished": "2018-01-01T09:54:18Z",
- "plan": "free",
- "costs": 12.98,
- "budget": 100,
- "usage": {
- "cpu": {
- "value": 40668,
- "unit": "cpu-seconds"
}, - "duration": {
- "value": 2611,
- "unit": "seconds"
}, - "memory": {
- "value": 108138811,
- "unit": "mb-seconds"
}, - "network": {
- "value": 0,
- "unit": "kb"
}, - "storage": {
- "value": 55,
- "unit": "mb"
}
}, - "log_level": "warning",
- "links": [
- {
- "rel": "result",
- "type": "application/json",
- "title": "Batch Job Results",
}, - {
- "rel": "result",
- "type": "application/json",
- "title": "Batch Job Logs",
}
]
}
], - "links": [
]
}Create a new batch job
Creates a new batch processing task (job) from one or more (chained) processes at the back-end.
Processing the data does not start yet. The job status gets initialized
as created by default.
Authorizations:
Request Body schema: application/jsonrequired
Specifies the job details, e.g. the user-defined process and billing details.
| title | string or null (eo_title) A short description to easily distinguish entities. |
| description | string or null <commonmark> (eo_description) Detailed multi-line description to explain the entity. CommonMark 0.29 syntax MAY be used for rich text representation. |
required | object (Process Graph with metadata) A process graph, optionally enriched with process metadata. |
| plan | string or null (billing_plan_null_default) Default: null The billing plan to process and charge the job or service with. Billing plans MUST be accepted in a case insensitive manner. Back-ends MUST resolve the billing plan in the following way:
The resolved plan MUST be persisted permanently, regardless of any
changes to the exposed billing plans in Billing plans not on the list of available plans MUST be rejected with
openEO error |
| budget | number or null (budget) >= 0 Default: null Maximum amount of costs the request is allowed to produce.
The value MUST be specified in the currency of the back-end.
No limits apply, if the value is |
| log_level | string (min_log_level_default) Default: "info" Enum: "error" "warning" "info" "debug" The minimum severity level for log entries that the back-end stores for the processing request. The order of the levels is as follows (from low to high severity): The default minimum log level is |
| property name* additional property | any Additional back-end specific properties are allowed. |
Responses
| Location required | string <uri> Example: "https://openeo.example/api/v1/jobs/123" Absolute URL to the newly created batch job. The URL points to the metadata endpoint
|
| OpenEO-Identifier required | string (job_id) ^[\w\-\.~]+$ Example: "a3cca2b2aa1e3b5b" Per-back-end unique identifier of the batch job, generated by the back-end during creation. MUST match the specified pattern. |
Request samples
- Payload
{- "title": "NDVI based on Sentinel-2",
- "description": "Deriving minimum NDVI measurements over pixel time series of Sentinel-2",
- "process": {
- "id": "ndvi",
- "summary": "string",
- "description": "string",
- "parameters": [
- {
- "schema": {
- "subtype": "string",
- "deprecated": false,
- "type": "string",
- "enum": [
- "a",
- "b"
]
}, - "name": "string",
- "description": "string",
- "optional": false,
- "deprecated": false,
- "experimental": false,
- "default": null
}
], - "returns": {
- "description": "string",
- "schema": {
- "subtype": "string",
- "deprecated": false,
- "type": "string",
- "enum": [
- "a",
- "b"
]
}
}, - "categories": [
- "string"
], - "deprecated": false,
- "experimental": false,
- "exceptions": {
- "Error Code1": {
- "description": "string",
- "message": "The value specified for the process argument '{argument}' in process '{process}' is invalid: {reason}",
- "http": 400
}, - "Error Code2": {
- "description": "string",
- "message": "The value specified for the process argument '{argument}' in process '{process}' is invalid: {reason}",
- "http": 400
}
}, - "examples": [
- {
- "title": "string",
- "description": "string",
- "arguments": {
- "property1": {
- "from_parameter": null,
- "from_node": null,
- "process_graph": null
}, - "property2": {
- "from_parameter": null,
- "from_node": null,
- "process_graph": null
}
}, - "returns": null
}
], - "links": [
], - "process_graph": {
- "dc": {
- "process_id": "load_collection",
- "arguments": {
- "id": "Sentinel-2",
- "spatial_extent": {
- "west": 16.1,
- "east": 16.6,
- "north": 48.6,
- "south": 47.2
}, - "temporal_extent": [
- "2018-01-01",
- "2018-02-01"
]
}
}, - "bands": {
- "process_id": "filter_bands",
- "description": "Filter and order the bands. The order is important for the following reduce operation.",
- "arguments": {
- "data": {
- "from_node": "dc"
}, - "bands": [
- "B08",
- "B04",
- "B02"
]
}
}, - "evi": {
- "process_id": "reduce",
- "description": "Compute the EVI. Formula: 2.5 * (NIR - RED) / (1 + NIR + 6*RED + -7.5*BLUE)",
- "arguments": {
- "data": {
- "from_node": "bands"
}, - "dimension": "bands",
- "reducer": {
- "process_graph": {
- "nir": {
- "process_id": "array_element",
- "arguments": {
- "data": {
- "from_parameter": "data"
}, - "index": 0
}
}, - "red": {
- "process_id": "array_element",
- "arguments": {
- "data": {
- "from_parameter": "data"
}, - "index": 1
}
}, - "blue": {
- "process_id": "array_element",
- "arguments": {
- "data": {
- "from_parameter": "data"
}, - "index": 2
}
}, - "sub": {
- "process_id": "subtract",
- "arguments": {
- "data": [
- {
- "from_node": "nir"
}, - {
- "from_node": "red"
}
]
}
}, - "p1": {
- "process_id": "product",
- "arguments": {
- "data": [
- 6,
- {
- "from_node": "red"
}
]
}
}, - "p2": {
- "process_id": "product",
- "arguments": {
- "data": [
- -7.5,
- {
- "from_node": "blue"
}
]
}
}, - "sum": {
- "process_id": "sum",
- "arguments": {
- "data": [
- 1,
- {
- "from_node": "nir"
}, - {
- "from_node": "p1"
}, - {
- "from_node": "p2"
}
]
}
}, - "div": {
- "process_id": "divide",
- "arguments": {
- "data": [
- {
- "from_node": "sub"
}, - {
- "from_node": "sum"
}
]
}
}, - "p3": {
- "process_id": "product",
- "arguments": {
- "data": [
- 2.5,
- {
- "from_node": "div"
}
]
}, - "result": true
}
}
}
}
}, - "mintime": {
- "process_id": "reduce",
- "description": "Compute a minimum time composite by reducing the temporal dimension",
- "arguments": {
- "data": {
- "from_node": "evi"
}, - "dimension": "temporal",
- "reducer": {
- "process_graph": {
- "min": {
- "process_id": "min",
- "arguments": {
- "data": {
- "from_parameter": "data"
}
}, - "result": true
}
}
}
}
}, - "save": {
- "process_id": "save_result",
- "arguments": {
- "data": {
- "from_node": "mintime"
}, - "format": "GTiff"
}, - "result": true
}
}
}, - "plan": "free",
- "budget": 100,
- "log_level": "warning",
- "property1": null,
- "property2": null
}Response samples
- 4XX
- 5XX
{- "id": "550e8400-e29b-11d4-a716-446655440000",
- "code": "SampleError",
- "message": "Parameter 'sample' is missing.",
}Modify a batch job
Modifies an existing job at the back-end, but maintains the identifier. Changes can be grouped in a single request.
The job status does not change.
Jobs can only be modified when the job is not queued and not running.
Otherwise, requests to this endpoint MUST be rejected with openEO error
JobLocked.
Authorizations:
path Parameters
| job_id required | string (job_id) ^[\w\-\.~]+$ Example: a3cca2b2aa1e3b5b Identifier of the batch job. |
Request Body schema: application/jsonrequired
Specifies the job details to update.
| title | string or null (eo_title) A short description to easily distinguish entities. |
| description | string or null <commonmark> (eo_description) Detailed multi-line description to explain the entity. CommonMark 0.29 syntax MAY be used for rich text representation. |
object (Process Graph with metadata) A process graph, optionally enriched with process metadata. | |
| plan | string or null (billing_plan_null) The billing plan to process and charge the job or service with. Billing plans MUST be accepted in a case insensitive manner. Back-ends MUST resolve the billing plan in the following way if billing is supported:
Billing plans not on the list of available plans MUST be rejected with
openEO error |
| budget | number or null (budget_update) >= 0 Maximum amount of costs the request is allowed to produce.
The value MUST be specified in the currency of the back-end.
No limits apply, if the value is |
| log_level | string (min_log_level_update) Enum: "error" "warning" "info" "debug" Updates the minimum severity level for log entries that the back-end stores for the processing requests. The back-end does not need to update existing log entries. |
| property name* additional property | any Additional back-end specific properties are allowed. |
Responses
Request samples
- Payload
{- "title": "NDVI based on Sentinel-2",
- "description": "Deriving minimum NDVI measurements over pixel time series of Sentinel-2",
- "process": {
- "id": "ndvi",
- "summary": "string",
- "description": "string",
- "parameters": [
- {
- "schema": {
- "subtype": "string",
- "deprecated": false,
- "type": "string",
- "enum": [
- "a",
- "b"
]
}, - "name": "string",
- "description": "string",
- "optional": false,
- "deprecated": false,
- "experimental": false,
- "default": null
}
], - "returns": {
- "description": "string",
- "schema": {
- "subtype": "string",
- "deprecated": false,
- "type": "string",
- "enum": [
- "a",
- "b"
]
}
}, - "categories": [
- "string"
], - "deprecated": false,
- "experimental": false,
- "exceptions": {
- "Error Code1": {
- "description": "string",
- "message": "The value specified for the process argument '{argument}' in process '{process}' is invalid: {reason}",
- "http": 400
}, - "Error Code2": {
- "description": "string",
- "message": "The value specified for the process argument '{argument}' in process '{process}' is invalid: {reason}",
- "http": 400
}
}, - "examples": [
- {
- "title": "string",
- "description": "string",
- "arguments": {
- "property1": {
- "from_parameter": null,
- "from_node": null,
- "process_graph": null
}, - "property2": {
- "from_parameter": null,
- "from_node": null,
- "process_graph": null
}
}, - "returns": null
}
], - "links": [
], - "process_graph": {
- "dc": {
- "process_id": "load_collection",
- "arguments": {
- "id": "Sentinel-2",
- "spatial_extent": {
- "west": 16.1,
- "east": 16.6,
- "north": 48.6,
- "south": 47.2
}, - "temporal_extent": [
- "2018-01-01",
- "2018-02-01"
]
}
}, - "bands": {
- "process_id": "filter_bands",
- "description": "Filter and order the bands. The order is important for the following reduce operation.",
- "arguments": {
- "data": {
- "from_node": "dc"
}, - "bands": [
- "B08",
- "B04",
- "B02"
]
}
}, - "evi": {
- "process_id": "reduce",
- "description": "Compute the EVI. Formula: 2.5 * (NIR - RED) / (1 + NIR + 6*RED + -7.5*BLUE)",
- "arguments": {
- "data": {
- "from_node": "bands"
}, - "dimension": "bands",
- "reducer": {
- "process_graph": {
- "nir": {
- "process_id": "array_element",
- "arguments": {
- "data": {
- "from_parameter": "data"
}, - "index": 0
}
}, - "red": {
- "process_id": "array_element",
- "arguments": {
- "data": {
- "from_parameter": "data"
}, - "index": 1
}
}, - "blue": {
- "process_id": "array_element",
- "arguments": {
- "data": {
- "from_parameter": "data"
}, - "index": 2
}
}, - "sub": {
- "process_id": "subtract",
- "arguments": {
- "data": [
- {
- "from_node": "nir"
}, - {
- "from_node": "red"
}
]
}
}, - "p1": {
- "process_id": "product",
- "arguments": {
- "data": [
- 6,
- {
- "from_node": "red"
}
]
}
}, - "p2": {
- "process_id": "product",
- "arguments": {
- "data": [
- -7.5,
- {
- "from_node": "blue"
}
]
}
}, - "sum": {
- "process_id": "sum",
- "arguments": {
- "data": [
- 1,
- {
- "from_node": "nir"
}, - {
- "from_node": "p1"
}, - {
- "from_node": "p2"
}
]
}
}, - "div": {
- "process_id": "divide",
- "arguments": {
- "data": [
- {
- "from_node": "sub"
}, - {
- "from_node": "sum"
}
]
}
}, - "p3": {
- "process_id": "product",
- "arguments": {
- "data": [
- 2.5,
- {
- "from_node": "div"
}
]
}, - "result": true
}
}
}
}
}, - "mintime": {
- "process_id": "reduce",
- "description": "Compute a minimum time composite by reducing the temporal dimension",
- "arguments": {
- "data": {
- "from_node": "evi"
}, - "dimension": "temporal",
- "reducer": {
- "process_graph": {
- "min": {
- "process_id": "min",
- "arguments": {
- "data": {
- "from_parameter": "data"
}
}, - "result": true
}
}
}
}
}, - "save": {
- "process_id": "save_result",
- "arguments": {
- "data": {
- "from_node": "mintime"
}, - "format": "GTiff"
}, - "result": true
}
}
}, - "plan": "free",
- "budget": 100,
- "log_level": "warning",
- "property1": null,
- "property2": null
}Response samples
- 4XX
- 5XX
{- "id": "550e8400-e29b-11d4-a716-446655440000",
- "code": "SampleError",
- "message": "Parameter 'sample' is missing.",
}Full metadata for a batch job
Lists all information about a submitted batch job.
Authorizations:
path Parameters
| job_id required | string (job_id) ^[\w\-\.~]+$ Example: a3cca2b2aa1e3b5b Identifier of the batch job. |
Responses
Response Schema: application/json
| id required | string (job_id) ^[\w\-\.~]+$ Per-back-end unique identifier of the batch job, generated by the back-end during creation. MUST match the specified pattern. |
| title | string or null (eo_title) A short description to easily distinguish entities. |
| description | string or null <commonmark> (eo_description) Detailed multi-line description to explain the entity. CommonMark 0.29 syntax MAY be used for rich text representation. |
required | object (Process Graph with metadata) A process graph, optionally enriched with process metadata. |
| status required | string Default: "created" Enum: "created" "queued" "running" "canceled" "finished" "error" The current status of a batch job. The following status changes can occur:
The following state diagram shows the possible status changes:
|
| progress | number [ 0 .. 100 ] Indicates the process of a running batch job, in percent.
Can also be set for a job which stopped due to an error or was canceled by the user. In this case, the value indicates the progress at which the job stopped. This property may not be available for the status codes |
| created required | string <date-time> (created) Date and time of creation (for batch jobs: the status 'created' was set), formatted as a RFC 3339 date-time. |
| updated | string <date-time> (updated) Date and time of the last status change, formatted as a RFC 3339 date-time. If the status is |
| queued | string <date-time> (queued) Date and time of queueing the batch job (i.e., when the status 'queued' was set), formatted as a RFC 3339 date-time. |
| started | string <date-time> (started) Date and time when the batch job started processing (i.e., when the status 'running' was set), formatted as a RFC 3339 date-time. |
| unpublished | string <date-time> (unpublished) Time until which the batch job results are stored on the back-end, in UTC. Formatted as a RFC 3339 date-time. |
| plan | string (billing_plan) The billing plan to process and charge the job or service with. Billing plans MUST be handled in a case insensitive manner. The plans can be retrieved from |
| costs | number or null (money) >= 0 Default: null An amount of money or credits. The value MUST be specified in the currency the back-end is working with. The currency can be retrieved by calling |
| budget | number or null (budget) >= 0 Default: null Maximum amount of costs the request is allowed to produce.
The value MUST be specified in the currency of the back-end.
No limits apply, if the value is |
object (Resource usage metrics) Metrics about the resource usage of the batch job. Back-ends are not expected to update the metrics while processing data,
so the metrics can only be available after the job has finished
or has stopped due to an error.
For usage metrics during processing, metrics can better be added to the
logs (e.g. | |
| log_level | string (min_log_level_default) Default: "info" Enum: "error" "warning" "info" "debug" The minimum severity level for log entries that the back-end stores for the processing request. The order of the levels is as follows (from low to high severity): The default minimum log level is |
Array of objects (Link) Links related to this batch job such as links to invoices, log files or results. Providing links with the following
The relation types
For more relation types see the lists of common relation types in openEO. | |
| property name* additional property | any You can list additional back-end specific properties here. |
{kind=link}
Response samples
- 200
- 4XX
- 5XX
{- "property1": null,
- "property2": null,
- "id": "a3cca2b2aa1e3b5b",
- "title": "NDVI based on Sentinel-2",
- "description": "Deriving minimum NDVI measurements over pixel time series of Sentinel-2",
- "process": {
- "id": "ndvi",
- "summary": "string",
- "description": "string",
- "parameters": [
- {
- "schema": {
- "subtype": "string",
- "deprecated": false,
- "type": "string",
- "enum": [
- "a",
- "b"
]
}, - "name": "string",
- "description": "string",
- "optional": false,
- "deprecated": false,
- "experimental": false,
- "default": null
}
], - "returns": {
- "description": "string",
- "schema": {
- "subtype": "string",
- "deprecated": false,
- "type": "string",
- "enum": [
- "a",
- "b"
]
}
}, - "categories": [
- "string"
], - "deprecated": false,
- "experimental": false,
- "exceptions": {
- "Error Code1": {
- "description": "string",
- "message": "The value specified for the process argument '{argument}' in process '{process}' is invalid: {reason}",
- "http": 400
}, - "Error Code2": {
- "description": "string",
- "message": "The value specified for the process argument '{argument}' in process '{process}' is invalid: {reason}",
- "http": 400
}
}, - "examples": [
- {
- "title": "string",
- "description": "string",
- "arguments": {
- "property1": {
- "from_parameter": null,
- "from_node": null,
- "process_graph": null
}, - "property2": {
- "from_parameter": null,
- "from_node": null,
- "process_graph": null
}
}, - "returns": null
}
], - "links": [
], - "process_graph": {
- "dc": {
- "process_id": "load_collection",
- "arguments": {
- "id": "Sentinel-2",
- "spatial_extent": {
- "west": 16.1,
- "east": 16.6,
- "north": 48.6,
- "south": 47.2
}, - "temporal_extent": [
- "2018-01-01",
- "2018-02-01"
]
}
}, - "bands": {
- "process_id": "filter_bands",
- "description": "Filter and order the bands. The order is important for the following reduce operation.",
- "arguments": {
- "data": {
- "from_node": "dc"
}, - "bands": [
- "B08",
- "B04",
- "B02"
]
}
}, - "evi": {
- "process_id": "reduce",
- "description": "Compute the EVI. Formula: 2.5 * (NIR - RED) / (1 + NIR + 6*RED + -7.5*BLUE)",
- "arguments": {
- "data": {
- "from_node": "bands"
}, - "dimension": "bands",
- "reducer": {
- "process_graph": {
- "nir": {
- "process_id": "array_element",
- "arguments": {
- "data": {
- "from_parameter": "data"
}, - "index": 0
}
}, - "red": {
- "process_id": "array_element",
- "arguments": {
- "data": {
- "from_parameter": "data"
}, - "index": 1
}
}, - "blue": {
- "process_id": "array_element",
- "arguments": {
- "data": {
- "from_parameter": "data"
}, - "index": 2
}
}, - "sub": {
- "process_id": "subtract",
- "arguments": {
- "data": [
- {
- "from_node": "nir"
}, - {
- "from_node": "red"
}
]
}
}, - "p1": {
- "process_id": "product",
- "arguments": {
- "data": [
- 6,
- {
- "from_node": "red"
}
]
}
}, - "p2": {
- "process_id": "product",
- "arguments": {
- "data": [
- -7.5,
- {
- "from_node": "blue"
}
]
}
}, - "sum": {
- "process_id": "sum",
- "arguments": {
- "data": [
- 1,
- {
- "from_node": "nir"
}, - {
- "from_node": "p1"
}, - {
- "from_node": "p2"
}
]
}
}, - "div": {
- "process_id": "divide",
- "arguments": {
- "data": [
- {
- "from_node": "sub"
}, - {
- "from_node": "sum"
}
]
}
}, - "p3": {
- "process_id": "product",
- "arguments": {
- "data": [
- 2.5,
- {
- "from_node": "div"
}
]
}, - "result": true
}
}
}
}
}, - "mintime": {
- "process_id": "reduce",
- "description": "Compute a minimum time composite by reducing the temporal dimension",
- "arguments": {
- "data": {
- "from_node": "evi"
}, - "dimension": "temporal",
- "reducer": {
- "process_graph": {
- "min": {
- "process_id": "min",
- "arguments": {
- "data": {
- "from_parameter": "data"
}
}, - "result": true
}
}
}
}
}, - "save": {
- "process_id": "save_result",
- "arguments": {
- "data": {
- "from_node": "mintime"
}, - "format": "GTiff"
}, - "result": true
}
}
}, - "status": "running",
- "progress": 75.5,
- "created": "2017-01-01T09:32:12Z",
- "updated": "2017-01-01T09:54:18Z",
- "queued": "2017-01-01T09:34:00Z",
- "started": "2017-01-01T09:36:18Z",
- "unpublished": "2018-01-01T09:54:18Z",
- "plan": "free",
- "costs": 12.98,
- "budget": 100,
- "usage": {
- "cpu": {
- "value": 40668,
- "unit": "cpu-seconds"
}, - "duration": {
- "value": 2611,
- "unit": "seconds"
}, - "memory": {
- "value": 108138811,
- "unit": "mb-seconds"
}, - "network": {
- "value": 0,
- "unit": "kb"
}, - "storage": {
- "value": 55,
- "unit": "mb"
}
}, - "log_level": "warning",
- "links": [
- {
- "rel": "result",
- "type": "application/json",
- "title": "Batch Job Results",
}, - {
- "rel": "result",
- "type": "application/json",
- "title": "Batch Job Logs",
}
]
}Delete a batch job
Deletes all data related to a given batch job. Computations are stopped and computed results are deleted. This job will not generate additional costs for processing.
Authorizations:
path Parameters
| job_id required | string (job_id) ^[\w\-\.~]+$ Example: a3cca2b2aa1e3b5b Identifier of the batch job. |
Responses
Response samples
- 4XX
- 5XX
{- "id": "550e8400-e29b-11d4-a716-446655440000",
- "code": "SampleError",
- "message": "Parameter 'sample' is missing.",
}Get an estimate for a batch job
Calculates an estimate for a batch job. Back-ends can decide to either calculate the duration, the costs, the size or a combination of them.
Back-end providers MAY specify an expiry time for the estimate. Starting to process data afterwards MAY be charged at a higher cost. Costs do often not include download costs. Whether download costs are included or not can be indicated explicitly with the downloads_included flag.
The estimate SHOULD be the upper limit of the costs, but back-end are free to use the field according to their terms of service.
For some batch jobs it is not (easily) possible to estimate the costs reliably, e.g. if a UDF or ML model is part of the process. In this case, the server SHOULD return a EstimateComplexity error with HTTP status code 500.
Authorizations:
path Parameters
| job_id required | string (job_id) ^[\w\-\.~]+$ Example: a3cca2b2aa1e3b5b Identifier of the batch job. |
Responses
Response Schema: application/json
| costs required | number or null (money) >= 0 Default: null An amount of money or credits. The value MUST be specified in the currency the back-end is working with. The currency can be retrieved by calling |
| duration | string Estimated duration for the operation. Duration MUST be specified as an ISO 8601 duration. |
| size | integer Estimated required storage capacity, i.e. the size of the generated files. Size MUST be specified in bytes. |
| downloads_included | integer or null Default: null Specifies how many full downloads of the processed data are included in the estimate. Set to |
| expires | string <date-time> Time until which the estimate is valid, formatted as a RFC 3339 date-time. |
Response samples
- 200
- 4XX
- 5XX
{- "costs": 12.98,
- "duration": "P1Y2M10DT2H30M",
- "size": 157286400,
- "downloads_included": 5,
- "expires": "2020-11-01T00:00:00Z"
}Logs for a batch job
Lists log entries for the batch job, usually for debugging purposes.
Back-ends can log any information that may be relevant for a user
at any stage (status) of the batch job.
Users can log information during data processing using respective
processes such as inspect.
If requested consecutively, it is RECOMMENDED that clients use the offset parameter to get only the entries they have not received yet.
While pagination itself is OPTIONAL, the offset parameter is REQUIRED
to be implemented by back-ends.
Authorizations:
path Parameters
| job_id required | string (job_id) ^[\w\-\.~]+$ Example: a3cca2b2aa1e3b5b Identifier of the batch job. |
query Parameters
| offset | string Example: offset=log1234 The last identifier (property |
| level | string Default: "debug" Enum: "error" "warning" "info" "debug" Example: level=error The minimum severity level for log entries that the back-end returns. The order of the levels is as follows (from low to high severity): The default minimum log level is |
| limit | integer >= 1 Example: limit=10 This parameter enables pagination for the endpoint and specifies the maximum number of
elements that arrays in the top-level object (e.g. collections, processes, batch jobs,
secondary services, log entries, etc.) are allowed to contain.
The Pagination is OPTIONAL: back-ends or clients may not support it. Therefore, it MUST be implemented in a way that clients not supporting pagination get all resources regardless. Back-ends not supporting pagination MUST return all resources. If the response is paginated, the |
Responses
Response Schema: application/json
| level | string Default: "debug" Enum: "error" "warning" "info" "debug" The minimum severity level for log entries that the back-end returns.
This property MUST reflect the effective lowest
The order of the levels is as follows (from low to high severity): |
required | Array of objects (Log Entry) A chronological list of logs. |
required | Array of objects (links_pagination) Links related to this list of resources, for example links for pagination or alternative formats such as a human-readable HTML version. The links array MUST NOT be paginated. If pagination is implemented, the following
For additional relation types see also the lists of common relation types in openEO. |
Response samples
- 200
- 4XX
- 5XX
{- "level": "error",
- "logs": [
- {
- "id": "1",
- "code": "SampleError",
- "level": "error",
- "message": "Can not load the UDF file from the URL `https://openeo.example/invalid/file.txt`. Server responded with error 404.",
- "time": "2019-08-24T14:15:22Z",
- "data": null,
- "path": [
- {
- "node_id": "runudf1",
- "process_id": "ndvi",
- "namespace": null,
- "parameter": "udf"
}
], - "usage": {
- "cpu": {
- "value": 40668,
- "unit": "cpu-seconds"
}, - "duration": {
- "value": 2611,
- "unit": "seconds"
}, - "memory": {
- "value": 108138811,
- "unit": "mb-seconds"
}, - "network": {
- "value": 0,
- "unit": "kb"
}, - "storage": {
- "value": 55,
- "unit": "mb"
}
}, - "stacktrace": "string",
}
], - "links": [
]
}List batch job results
Lists signed URLs pointing to the processed files, usually after the batch job
has finished. Back-ends may also point to intermediate results after the
job has stopped due to an error or if the partial parameter has been set.
The response includes additional metadata. It is a valid
STAC Item
(if it has spatial and temporal references included) or a valid
STAC Collection
(supported since openEO API version 1.1.0).
The assets to download are in both cases available in the property assets
and have the same structure. Additional metadata is not strictly required
to download the files, but are helpful for users to understand the data.
STAC Collections can either (1) add all assets as collection-level assets or
(2) link to STAC Catalogs and STAC Items with signed URLs, which will provide a full
STAC catalog structure a client has to go through. Option 2 is overall the better
architectural choice and allows a fine-grained description of the processed data,
but it is not compliant with previous versions of the openEO API.
To maintain backward compatibility, it is REQUIRED to still copy
all assets in the STAC catalog structure into the collection-level assets.
This requirement is planned to be removed in openEO API version 2.0.0.
A client can enforce that the server returns a GeoJSON through content negotiation
with the media type application/geo+json, but the results may not contain very
meaningful metadata aside from the assets.
Clients are RECOMMENDED to store this response and all potential sub-catalogs and items with the assets so that the downloaded data is then a self-contained STAC catalog user could publish easily with all the data and metadata.
URL signing is a way to protect files from unauthorized access with a
key in the URL instead of HTTP header based authorization. The URL
signing key is similar to a password and its inclusion in the URL allows
to download files using simple GET requests supported by a wide range of
programs, e.g. web browsers or download managers. Back-ends are
responsible to generate the URL signing keys and to manage their
appropriate expiration. The back-end MAY indicate an expiration time by
setting the expires property in the reponse. Requesting this endpoint
SHOULD always return non-expired URLs. Signed URLs that were generated
for a previous request and already expired SHOULD NOT be reused,
but regenerated with new expiration time.
Signed URLs that expired MAY return the openEO error ResultLinkExpired.
Adding a link with relation type canonical to the STAC Item or STAC Collection
is STRONGLY RECOMMENDED (see the links property for details).
If processing has not finished yet and the partial parameter is not set to true
requests to this endpoint MUST be rejected with openEO error JobNotFinished.
Authorizations:
path Parameters
| job_id required | string (job_id) ^[\w\-\.~]+$ Example: a3cca2b2aa1e3b5b Identifier of the batch job. |
query Parameters
| partial | boolean Default: false If set to |
Responses
| OpenEO-Costs | number or null (money) >= 0 Default: null Example: "12.98" Specifies the costs for fully downloading the data once, i.e. this header MAY change in subsequent calls. It MUST be set to |
Response Schema:
| stac_version required | string (stac_version) ^(0\.9.\d+|1\.\d+.\d+) The version of the STAC specification, which MAY not be equal to the STAC API version. The openEO API allows for the STAC versions 1.x.x (RECOMMENDED) and 0.9.x (DEPRECATED). |
Array of Reference to a JSON Schema (string) or Reference to a core extension (STAC < 1.0.0-rc.1 only, DEPRECATED) (string) (stac_extensions) unique A list of implemented STAC extensions. The list contains URLs to the JSON Schema files it can be validated against. | |
| id required | string (job_id) ^[\w\-\.~]+$ Per-back-end unique identifier of the batch job, generated by the back-end during creation. MUST match the specified pattern. |
| type required | string Value: "Feature" The GeoJSON type that applies to this metadata document, which MUST always be a "Feature" according to the STAC specification. This type does not describe the spatial data type of the assets. |
Array of 4 elements (numbers) or Array of 6 elements (numbers) (bbox) Each bounding box is provided as four or six numbers, depending on whether the coordinate reference system includes a vertical axis (height or depth):
The coordinate reference system of the values is WGS 84 longitude/latitude (http://www.opengis.net/def/crs/OGC/1.3/CRS84). For WGS 84 longitude/latitude the values are in most cases the sequence of minimum longitude, minimum latitude, maximum longitude and maximum latitude. However, in cases where the box spans the antimeridian the first value (west-most box edge) is larger than the third value (east-most box edge). If the vertical axis is included, the third and the sixth number are the bottom and the top of the 3-dimensional bounding box. | |
required | object or null (GeoJSON Geometry) Defines the full footprint of the asset represented by this item as GeoJSON Geometry. Results without a known location can set this value to |
required | object (Item Properties) MAY contain additional properties other than the required property |
required | object (Assets) Dictionary of asset objects for data that can be downloaded, each with a unique key. The keys MAY be used by clients as file names. |
required | Array of objects (Link) Links related to this batch job result, e.g. a link to an invoice, additional log files or external documentation. The links MUST NOT contain links to the processed and
downloadable data. Instead specify these in the It is strongly recommended to add a link with relation type
For relation types see the lists of common relation types in openEO. |
Response samples
- 200
- 424
- 4XX
- 5XX
{- "stac_version": "1.1.0",
- "id": "a3cca2b2aa1e3b5b",
- "type": "Feature",
- "bbox": [
- -180,
- -90,
- 180,
- 90
], - "geometry": {
- "type": "Polygon",
- "coordinates": [
- [
- [
- -180,
- -90
], - [
- 180,
- -90
], - [
- 180,
- 90
], - [
- -180,
- 90
], - [
- -180,
- -90
]
]
]
}, - "properties": {
- "datetime": "2019-08-24T14:15:22Z",
- "start_datetime": "2019-08-24T14:15:22Z",
- "end_datetime": "2019-08-24T14:15:22Z",
- "title": "NDVI based on Sentinel-2",
- "description": "Deriving minimum NDVI measurements over pixel time series of Sentinel-2",
- "license": "Apache-2.0",
- "providers": [
- {
- "name": "Example Cloud Corp.",
- "description": "No further processing applied.",
- "roles": [
- "producer",
- "licensor",
- "host"
],
}
], - "created": "2017-01-01T09:32:12Z",
- "updated": "2017-01-01T09:54:18Z",
- "queued": "2017-01-01T09:34:00Z",
- "started": "2017-01-01T09:36:18Z",
- "expires": "2017-02-01T09:54:18Z",
- "unpublished": "2018-01-01T09:54:18Z",
- "openeo:status": "running"
}, - "assets": {
- "preview.png": {
- "type": "image/png",
- "title": "Thumbnail",
- "roles": [
- "thumbnail"
]
}, - "process.json": {
- "type": "application/json",
- "title": "Original Process",
- "roles": [
- "process",
- "reproduction"
]
}, - "1.tif": {
- "type": "image/tiff; application=geotiff",
- "title": "Band 1",
- "roles": [
- "data"
]
}, - "2.tif": {
- "type": "image/tiff; application=geotiff",
- "title": "Band 2",
- "roles": [
- "data"
]
}, - "inspire.xml": {
- "type": "application/xml",
- "title": "INSPIRE metadata",
- "description": "INSPIRE compliant XML metadata",
- "roles": [
- "metadata"
]
}
}, - "links": [
- {
- "rel": "canonical",
- "type": "application/geo+json",
}
]
}{kind=link}
Start processing a batch job
Adds a batch job to the processing queue to compute the results.
The result will be stored in the format specified in the process.
To specify the format use a process such as save_result.
The job status is set to queued, if processing does not start
instantly. The same applies if the job status is canceled, finished,
or error, which restarts the job and discards previous results if the
back-end does not reject the request with an error.
Clients SHOULD warn users and ask for confirmation if results may get
discarded.
- Once the processing starts the status is set to
running. - Once the data is available to download the status is set to
finished. - Whenever an error occurs during processing, the status MUST be set to
error.
This endpoint has no effect if the job status is already queued or
running. In particular, it does not restart a running job. To restart
a queued or running job, processing MUST have been canceled.
Back-ends SHOULD reject queueing jobs with openEO error PaymentRequired,
if the back-end is able to detect that the budget is too low to fully
process the request. Alternatively, back-ends MAY provide partial results
once reaching the budget. If none of the alternatives is feasible, the
results are discarded. Thus, client SHOULD warn users that reaching the
budget may lead to partial or no results at all.
Authorizations:
path Parameters
| job_id required | string (job_id) ^[\w\-\.~]+$ Example: a3cca2b2aa1e3b5b Identifier of the batch job. |
Responses
Response samples
- 4XX
- 5XX
{- "id": "550e8400-e29b-11d4-a716-446655440000",
- "code": "SampleError",
- "message": "Parameter 'sample' is missing.",
}Cancel processing a batch job
Cancels all related computations for this job at the back-end. It will stop generating additional costs for processing.
A subset of processed results may be available for downloading depending on the state of the job at the time it was canceled.
Results MUST NOT be deleted until the job processing is started again or
the job is completely deleted through a request to
DELETE /jobs/{job_id}.
This endpoint only has an effect if the job status is queued or
running.
The job status is set to canceled if the status was running
beforehand and partial or preliminary results are available to be
downloaded. Otherwise the status is set to created.
Authorizations:
path Parameters
| job_id required | string (job_id) ^[\w\-\.~]+$ Example: a3cca2b2aa1e3b5b Identifier of the batch job. |
Responses
Response samples
- 4XX
- 5XX
{- "id": "550e8400-e29b-11d4-a716-446655440000",
- "code": "SampleError",
- "message": "Parameter 'sample' is missing.",
}List all batch jobs
Lists all batch jobs submitted by a user.
It is strongly RECOMMENDED to keep the response size small by
omitting all optional non-scalar values (i.e. arrays and objects) from
objects in jobs (i.e. the process property).
To get the full metadata for a job clients MUST request GET /jobs/{job_id}.
Authorizations:
query Parameters
| limit | integer >= 1 Example: limit=10 This parameter enables pagination for the endpoint and specifies the maximum number of
elements that arrays in the top-level object (e.g. collections, processes, batch jobs,
secondary services, log entries, etc.) are allowed to contain.
The Pagination is OPTIONAL: back-ends or clients may not support it. Therefore, it MUST be implemented in a way that clients not supporting pagination get all resources regardless. Back-ends not supporting pagination MUST return all resources. If the response is paginated, the |
Responses
Response Schema: application/json
required | Array of objects (Batch Job) |
required | Array of objects (links_pagination) Links related to this list of resources, for example links for pagination or alternative formats such as a human-readable HTML version. The links array MUST NOT be paginated. If pagination is implemented, the following
For additional relation types see also the lists of common relation types in openEO. |
Response samples
- 200
- 4XX
- 5XX
{- "jobs": [
- {
- "id": "a3cca2b2aa1e3b5b",
- "title": "NDVI based on Sentinel-2",
- "description": "Deriving minimum NDVI measurements over pixel time series of Sentinel-2",
- "process": {
- "id": "ndvi",
- "summary": "string",
- "description": "string",
- "parameters": [
- {
- "schema": {
- "subtype": "string",
- "deprecated": false,
- "type": "string",
- "enum": [
- "a",
- "b"
]
}, - "name": "string",
- "description": "string",
- "optional": false,
- "deprecated": false,
- "experimental": false,
- "default": null
}
], - "returns": {
- "description": "string",
- "schema": {
- "subtype": "string",
- "deprecated": false,
- "type": "string",
- "enum": [
- "a",
- "b"
]
}
}, - "categories": [
- "string"
], - "deprecated": false,
- "experimental": false,
- "exceptions": {
- "Error Code1": {
- "description": "string",
- "message": "The value specified for the process argument '{argument}' in process '{process}' is invalid: {reason}",
- "http": 400
}, - "Error Code2": {
- "description": "string",
- "message": "The value specified for the process argument '{argument}' in process '{process}' is invalid: {reason}",
- "http": 400
}
}, - "examples": [
- {
- "title": "string",
- "description": "string",
- "arguments": {
- "property1": {
- "from_parameter": null,
- "from_node": null,
- "process_graph": null
}, - "property2": {
- "from_parameter": null,
- "from_node": null,
- "process_graph": null
}
}, - "returns": null
}
], - "links": [
], - "process_graph": {
- "dc": {
- "process_id": "load_collection",
- "arguments": {
- "id": "Sentinel-2",
- "spatial_extent": {
- "west": 16.1,
- "east": 16.6,
- "north": 48.6,
- "south": 47.2
}, - "temporal_extent": [
- "2018-01-01",
- "2018-02-01"
]
}
}, - "bands": {
- "process_id": "filter_bands",
- "description": "Filter and order the bands. The order is important for the following reduce operation.",
- "arguments": {
- "data": {
- "from_node": "dc"
}, - "bands": [
- "B08",
- "B04",
- "B02"
]
}
}, - "evi": {
- "process_id": "reduce",
- "description": "Compute the EVI. Formula: 2.5 * (NIR - RED) / (1 + NIR + 6*RED + -7.5*BLUE)",
- "arguments": {
- "data": {
- "from_node": "bands"
}, - "dimension": "bands",
- "reducer": {
- "process_graph": {
- "nir": {
- "process_id": "array_element",
- "arguments": {
- "data": {
- "from_parameter": "data"
}, - "index": 0
}
}, - "red": {
- "process_id": "array_element",
- "arguments": {
- "data": {
- "from_parameter": "data"
}, - "index": 1
}
}, - "blue": {
- "process_id": "array_element",
- "arguments": {
- "data": {
- "from_parameter": "data"
}, - "index": 2
}
}, - "sub": {
- "process_id": "subtract",
- "arguments": {
- "data": [
- {
- "from_node": "nir"
}, - {
- "from_node": "red"
}
]
}
}, - "p1": {
- "process_id": "product",
- "arguments": {
- "data": [
- 6,
- {
- "from_node": "red"
}
]
}
}, - "p2": {
- "process_id": "product",
- "arguments": {
- "data": [
- -7.5,
- {
- "from_node": "blue"
}
]
}
}, - "sum": {
- "process_id": "sum",
- "arguments": {
- "data": [
- 1,
- {
- "from_node": "nir"
}, - {
- "from_node": "p1"
}, - {
- "from_node": "p2"
}
]
}
}, - "div": {
- "process_id": "divide",
- "arguments": {
- "data": [
- {
- "from_node": "sub"
}, - {
- "from_node": "sum"
}
]
}
}, - "p3": {
- "process_id": "product",
- "arguments": {
- "data": [
- 2.5,
- {
- "from_node": "div"
}
]
}, - "result": true
}
}
}
}
}, - "mintime": {
- "process_id": "reduce",
- "description": "Compute a minimum time composite by reducing the temporal dimension",
- "arguments": {
- "data": {
- "from_node": "evi"
}, - "dimension": "temporal",
- "reducer": {
- "process_graph": {
- "min": {
- "process_id": "min",
- "arguments": {
- "data": {
- "from_parameter": "data"
}
}, - "result": true
}
}
}
}
}, - "save": {
- "process_id": "save_result",
- "arguments": {
- "data": {
- "from_node": "mintime"
}, - "format": "GTiff"
}, - "result": true
}
}
}, - "status": "running",
- "progress": 75.5,
- "created": "2017-01-01T09:32:12Z",
- "updated": "2017-01-01T09:54:18Z",
- "queued": "2017-01-01T09:34:00Z",
- "started": "2017-01-01T09:36:18Z",
- "unpublished": "2018-01-01T09:54:18Z",
- "plan": "free",
- "costs": 12.98,
- "budget": 100,
- "usage": {
- "cpu": {
- "value": 40668,
- "unit": "cpu-seconds"
}, - "duration": {
- "value": 2611,
- "unit": "seconds"
}, - "memory": {
- "value": 108138811,
- "unit": "mb-seconds"
}, - "network": {
- "value": 0,
- "unit": "kb"
}, - "storage": {
- "value": 55,
- "unit": "mb"
}
}, - "log_level": "warning",
- "links": [
- {
- "rel": "result",
- "type": "application/json",
- "title": "Batch Job Results",
}, - {
- "rel": "result",
- "type": "application/json",
- "title": "Batch Job Logs",
}
]
}
], - "links": [
]
}Create a new batch job
Creates a new batch processing task (job) from one or more (chained) processes at the back-end.
Processing the data does not start yet. The job status gets initialized
as created by default.
Authorizations:
Request Body schema: application/jsonrequired
Specifies the job details, e.g. the user-defined process and billing details.
| title | string or null (eo_title) A short description to easily distinguish entities. |
| description | string or null <commonmark> (eo_description) Detailed multi-line description to explain the entity. CommonMark 0.29 syntax MAY be used for rich text representation. |
required | object (Process Graph with metadata) A process graph, optionally enriched with process metadata. |
| plan | string or null (billing_plan_null_default) Default: null The billing plan to process and charge the job or service with. Billing plans MUST be accepted in a case insensitive manner. Back-ends MUST resolve the billing plan in the following way:
The resolved plan MUST be persisted permanently, regardless of any
changes to the exposed billing plans in Billing plans not on the list of available plans MUST be rejected with
openEO error |
| budget | number or null (budget) >= 0 Default: null Maximum amount of costs the request is allowed to produce.
The value MUST be specified in the currency of the back-end.
No limits apply, if the value is |
| log_level | string (min_log_level_default) Default: "info" Enum: "error" "warning" "info" "debug" The minimum severity level for log entries that the back-end stores for the processing request. The order of the levels is as follows (from low to high severity): The default minimum log level is |
| property name* additional property | any Additional back-end specific properties are allowed. |
Responses
| Location required | string <uri> Example: "https://openeo.example/api/v1/jobs/123" Absolute URL to the newly created batch job. The URL points to the metadata endpoint
|
| OpenEO-Identifier required | string (job_id) ^[\w\-\.~]+$ Example: "a3cca2b2aa1e3b5b" Per-back-end unique identifier of the batch job, generated by the back-end during creation. MUST match the specified pattern. |
Request samples
- Payload
{- "title": "NDVI based on Sentinel-2",
- "description": "Deriving minimum NDVI measurements over pixel time series of Sentinel-2",
- "process": {
- "id": "ndvi",
- "summary": "string",
- "description": "string",
- "parameters": [
- {
- "schema": {
- "subtype": "string",
- "deprecated": false,
- "type": "string",
- "enum": [
- "a",
- "b"
]
}, - "name": "string",
- "description": "string",
- "optional": false,
- "deprecated": false,
- "experimental": false,
- "default": null
}
], - "returns": {
- "description": "string",
- "schema": {
- "subtype": "string",
- "deprecated": false,
- "type": "string",
- "enum": [
- "a",
- "b"
]
}
}, - "categories": [
- "string"
], - "deprecated": false,
- "experimental": false,
- "exceptions": {
- "Error Code1": {
- "description": "string",
- "message": "The value specified for the process argument '{argument}' in process '{process}' is invalid: {reason}",
- "http": 400
}, - "Error Code2": {
- "description": "string",
- "message": "The value specified for the process argument '{argument}' in process '{process}' is invalid: {reason}",
- "http": 400
}
}, - "examples": [
- {
- "title": "string",
- "description": "string",
- "arguments": {
- "property1": {
- "from_parameter": null,
- "from_node": null,
- "process_graph": null
}, - "property2": {
- "from_parameter": null,
- "from_node": null,
- "process_graph": null
}
}, - "returns": null
}
], - "links": [
], - "process_graph": {
- "dc": {
- "process_id": "load_collection",
- "arguments": {
- "id": "Sentinel-2",
- "spatial_extent": {
- "west": 16.1,
- "east": 16.6,
- "north": 48.6,
- "south": 47.2
}, - "temporal_extent": [
- "2018-01-01",
- "2018-02-01"
]
}
}, - "bands": {
- "process_id": "filter_bands",
- "description": "Filter and order the bands. The order is important for the following reduce operation.",
- "arguments": {
- "data": {
- "from_node": "dc"
}, - "bands": [
- "B08",
- "B04",
- "B02"
]
}
}, - "evi": {
- "process_id": "reduce",
- "description": "Compute the EVI. Formula: 2.5 * (NIR - RED) / (1 + NIR + 6*RED + -7.5*BLUE)",
- "arguments": {
- "data": {
- "from_node": "bands"
}, - "dimension": "bands",
- "reducer": {
- "process_graph": {
- "nir": {
- "process_id": "array_element",
- "arguments": {
- "data": {
- "from_parameter": "data"
}, - "index": 0
}
}, - "red": {
- "process_id": "array_element",
- "arguments": {
- "data": {
- "from_parameter": "data"
}, - "index": 1
}
}, - "blue": {
- "process_id": "array_element",
- "arguments": {
- "data": {
- "from_parameter": "data"
}, - "index": 2
}
}, - "sub": {
- "process_id": "subtract",
- "arguments": {
- "data": [
- {
- "from_node": "nir"
}, - {
- "from_node": "red"
}
]
}
}, - "p1": {
- "process_id": "product",
- "arguments": {
- "data": [
- 6,
- {
- "from_node": "red"
}
]
}
}, - "p2": {
- "process_id": "product",
- "arguments": {
- "data": [
- -7.5,
- {
- "from_node": "blue"
}
]
}
}, - "sum": {
- "process_id": "sum",
- "arguments": {
- "data": [
- 1,
- {
- "from_node": "nir"
}, - {
- "from_node": "p1"
}, - {
- "from_node": "p2"
}
]
}
}, - "div": {
- "process_id": "divide",
- "arguments": {
- "data": [
- {
- "from_node": "sub"
}, - {
- "from_node": "sum"
}
]
}
}, - "p3": {
- "process_id": "product",
- "arguments": {
- "data": [
- 2.5,
- {
- "from_node": "div"
}
]
}, - "result": true
}
}
}
}
}, - "mintime": {
- "process_id": "reduce",
- "description": "Compute a minimum time composite by reducing the temporal dimension",
- "arguments": {
- "data": {
- "from_node": "evi"
}, - "dimension": "temporal",
- "reducer": {
- "process_graph": {
- "min": {
- "process_id": "min",
- "arguments": {
- "data": {
- "from_parameter": "data"
}
}, - "result": true
}
}
}
}
}, - "save": {
- "process_id": "save_result",
- "arguments": {
- "data": {
- "from_node": "mintime"
}, - "format": "GTiff"
}, - "result": true
}
}
}, - "plan": "free",
- "budget": 100,
- "log_level": "warning",
- "property1": null,
- "property2": null
}Response samples
- 4XX
- 5XX
{- "id": "550e8400-e29b-11d4-a716-446655440000",
- "code": "SampleError",
- "message": "Parameter 'sample' is missing.",
}Modify a batch job
Modifies an existing job at the back-end, but maintains the identifier. Changes can be grouped in a single request.
The job status does not change.
Jobs can only be modified when the job is not queued and not running.
Otherwise, requests to this endpoint MUST be rejected with openEO error
JobLocked.
Authorizations:
path Parameters
| job_id required | string (job_id) ^[\w\-\.~]+$ Example: a3cca2b2aa1e3b5b Identifier of the batch job. |
Request Body schema: application/jsonrequired
Specifies the job details to update.
| title | string or null (eo_title) A short description to easily distinguish entities. |
| description | string or null <commonmark> (eo_description) Detailed multi-line description to explain the entity. CommonMark 0.29 syntax MAY be used for rich text representation. |
object (Process Graph with metadata) A process graph, optionally enriched with process metadata. | |
| plan | string or null (billing_plan_null) The billing plan to process and charge the job or service with. Billing plans MUST be accepted in a case insensitive manner. Back-ends MUST resolve the billing plan in the following way if billing is supported:
Billing plans not on the list of available plans MUST be rejected with
openEO error |
| budget | number or null (budget_update) >= 0 Maximum amount of costs the request is allowed to produce.
The value MUST be specified in the currency of the back-end.
No limits apply, if the value is |
| log_level | string (min_log_level_update) Enum: "error" "warning" "info" "debug" Updates the minimum severity level for log entries that the back-end stores for the processing requests. The back-end does not need to update existing log entries. |
| property name* additional property | any Additional back-end specific properties are allowed. |
Responses
Request samples
- Payload
{- "title": "NDVI based on Sentinel-2",
- "description": "Deriving minimum NDVI measurements over pixel time series of Sentinel-2",
- "process": {
- "id": "ndvi",
- "summary": "string",
- "description": "string",
- "parameters": [
- {
- "schema": {
- "subtype": "string",
- "deprecated": false,
- "type": "string",
- "enum": [
- "a",
- "b"
]
}, - "name": "string",
- "description": "string",
- "optional": false,
- "deprecated": false,
- "experimental": false,
- "default": null
}
], - "returns": {
- "description": "string",
- "schema": {
- "subtype": "string",
- "deprecated": false,
- "type": "string",
- "enum": [
- "a",
- "b"
]
}
}, - "categories": [
- "string"
], - "deprecated": false,
- "experimental": false,
- "exceptions": {
- "Error Code1": {
- "description": "string",
- "message": "The value specified for the process argument '{argument}' in process '{process}' is invalid: {reason}",
- "http": 400
}, - "Error Code2": {
- "description": "string",
- "message": "The value specified for the process argument '{argument}' in process '{process}' is invalid: {reason}",
- "http": 400
}
}, - "examples": [
- {
- "title": "string",
- "description": "string",
- "arguments": {
- "property1": {
- "from_parameter": null,
- "from_node": null,
- "process_graph": null
}, - "property2": {
- "from_parameter": null,
- "from_node": null,
- "process_graph": null
}
}, - "returns": null
}
], - "links": [
], - "process_graph": {
- "dc": {
- "process_id": "load_collection",
- "arguments": {
- "id": "Sentinel-2",
- "spatial_extent": {
- "west": 16.1,
- "east": 16.6,
- "north": 48.6,
- "south": 47.2
}, - "temporal_extent": [
- "2018-01-01",
- "2018-02-01"
]
}
}, - "bands": {
- "process_id": "filter_bands",
- "description": "Filter and order the bands. The order is important for the following reduce operation.",
- "arguments": {
- "data": {
- "from_node": "dc"
}, - "bands": [
- "B08",
- "B04",
- "B02"
]
}
}, - "evi": {
- "process_id": "reduce",
- "description": "Compute the EVI. Formula: 2.5 * (NIR - RED) / (1 + NIR + 6*RED + -7.5*BLUE)",
- "arguments": {
- "data": {
- "from_node": "bands"
}, - "dimension": "bands",
- "reducer": {
- "process_graph": {
- "nir": {
- "process_id": "array_element",
- "arguments": {
- "data": {
- "from_parameter": "data"
}, - "index": 0
}
}, - "red": {
- "process_id": "array_element",
- "arguments": {
- "data": {
- "from_parameter": "data"
}, - "index": 1
}
}, - "blue": {
- "process_id": "array_element",
- "arguments": {
- "data": {
- "from_parameter": "data"
}, - "index": 2
}
}, - "sub": {
- "process_id": "subtract",
- "arguments": {
- "data": [
- {
- "from_node": "nir"
}, - {
- "from_node": "red"
}
]
}
}, - "p1": {
- "process_id": "product",
- "arguments": {
- "data": [
- 6,
- {
- "from_node": "red"
}
]
}
}, - "p2": {
- "process_id": "product",
- "arguments": {
- "data": [
- -7.5,
- {
- "from_node": "blue"
}
]
}
}, - "sum": {
- "process_id": "sum",
- "arguments": {
- "data": [
- 1,
- {
- "from_node": "nir"
}, - {
- "from_node": "p1"
}, - {
- "from_node": "p2"
}
]
}
}, - "div": {
- "process_id": "divide",
- "arguments": {
- "data": [
- {
- "from_node": "sub"
}, - {
- "from_node": "sum"
}
]
}
}, - "p3": {
- "process_id": "product",
- "arguments": {
- "data": [
- 2.5,
- {
- "from_node": "div"
}
]
}, - "result": true
}
}
}
}
}, - "mintime": {
- "process_id": "reduce",
- "description": "Compute a minimum time composite by reducing the temporal dimension",
- "arguments": {
- "data": {
- "from_node": "evi"
}, - "dimension": "temporal",
- "reducer": {
- "process_graph": {
- "min": {
- "process_id": "min",
- "arguments": {
- "data": {
- "from_parameter": "data"
}
}, - "result": true
}
}
}
}
}, - "save": {
- "process_id": "save_result",
- "arguments": {
- "data": {
- "from_node": "mintime"
}, - "format": "GTiff"
}, - "result": true
}
}
}, - "plan": "free",
- "budget": 100,
- "log_level": "warning",
- "property1": null,
- "property2": null
}Response samples
- 4XX
- 5XX
{- "id": "550e8400-e29b-11d4-a716-446655440000",
- "code": "SampleError",
- "message": "Parameter 'sample' is missing.",
}Full metadata for a batch job
Lists all information about a submitted batch job.
Authorizations:
path Parameters
| job_id required | string (job_id) ^[\w\-\.~]+$ Example: a3cca2b2aa1e3b5b Identifier of the batch job. |
Responses
Response Schema: application/json
| id required | string (job_id) ^[\w\-\.~]+$ Per-back-end unique identifier of the batch job, generated by the back-end during creation. MUST match the specified pattern. |
| title | string or null (eo_title) A short description to easily distinguish entities. |
| description | string or null <commonmark> (eo_description) Detailed multi-line description to explain the entity. CommonMark 0.29 syntax MAY be used for rich text representation. |
required | object (Process Graph with metadata) A process graph, optionally enriched with process metadata. |
| status required | string Default: "created" Enum: "created" "queued" "running" "canceled" "finished" "error" The current status of a batch job. The following status changes can occur:
The following state diagram shows the possible status changes:
|
| progress | number [ 0 .. 100 ] Indicates the process of a running batch job, in percent.
Can also be set for a job which stopped due to an error or was canceled by the user. In this case, the value indicates the progress at which the job stopped. This property may not be available for the status codes |
| created required | string <date-time> (created) Date and time of creation (for batch jobs: the status 'created' was set), formatted as a RFC 3339 date-time. |
| updated | string <date-time> (updated) Date and time of the last status change, formatted as a RFC 3339 date-time. If the status is |
| queued | string <date-time> (queued) Date and time of queueing the batch job (i.e., when the status 'queued' was set), formatted as a RFC 3339 date-time. |
| started | string <date-time> (started) Date and time when the batch job started processing (i.e., when the status 'running' was set), formatted as a RFC 3339 date-time. |
| unpublished | string <date-time> (unpublished) Time until which the batch job results are stored on the back-end, in UTC. Formatted as a RFC 3339 date-time. |
| plan | string (billing_plan) The billing plan to process and charge the job or service with. Billing plans MUST be handled in a case insensitive manner. The plans can be retrieved from |
| costs | number or null (money) >= 0 Default: null An amount of money or credits. The value MUST be specified in the currency the back-end is working with. The currency can be retrieved by calling |
| budget | number or null (budget) >= 0 Default: null Maximum amount of costs the request is allowed to produce.
The value MUST be specified in the currency of the back-end.
No limits apply, if the value is |
object (Resource usage metrics) Metrics about the resource usage of the batch job. Back-ends are not expected to update the metrics while processing data,
so the metrics can only be available after the job has finished
or has stopped due to an error.
For usage metrics during processing, metrics can better be added to the
logs (e.g. | |
| log_level | string (min_log_level_default) Default: "info" Enum: "error" "warning" "info" "debug" The minimum severity level for log entries that the back-end stores for the processing request. The order of the levels is as follows (from low to high severity): The default minimum log level is |
Array of objects (Link) Links related to this batch job such as links to invoices, log files or results. Providing links with the following
The relation types
For more relation types see the lists of common relation types in openEO. | |
| property name* additional property | any You can list additional back-end specific properties here. |
Response samples
- 200
- 4XX
- 5XX
{- "property1": null,
- "property2": null,
- "id": "a3cca2b2aa1e3b5b",
- "title": "NDVI based on Sentinel-2",
- "description": "Deriving minimum NDVI measurements over pixel time series of Sentinel-2",
- "process": {
- "id": "ndvi",
- "summary": "string",
- "description": "string",
- "parameters": [
- {
- "schema": {
- "subtype": "string",
- "deprecated": false,
- "type": "string",
- "enum": [
- "a",
- "b"
]
}, - "name": "string",
- "description": "string",
- "optional": false,
- "deprecated": false,
- "experimental": false,
- "default": null
}
], - "returns": {
- "description": "string",
- "schema": {
- "subtype": "string",
- "deprecated": false,
- "type": "string",
- "enum": [
- "a",
- "b"
]
}
}, - "categories": [
- "string"
], - "deprecated": false,
- "experimental": false,
- "exceptions": {
- "Error Code1": {
- "description": "string",
- "message": "The value specified for the process argument '{argument}' in process '{process}' is invalid: {reason}",
- "http": 400
}, - "Error Code2": {
- "description": "string",
- "message": "The value specified for the process argument '{argument}' in process '{process}' is invalid: {reason}",
- "http": 400
}
}, - "examples": [
- {
- "title": "string",
- "description": "string",
- "arguments": {
- "property1": {
- "from_parameter": null,
- "from_node": null,
- "process_graph": null
}, - "property2": {
- "from_parameter": null,
- "from_node": null,
- "process_graph": null
}
}, - "returns": null
}
], - "links": [
], - "process_graph": {
- "dc": {
- "process_id": "load_collection",
- "arguments": {
- "id": "Sentinel-2",
- "spatial_extent": {
- "west": 16.1,
- "east": 16.6,
- "north": 48.6,
- "south": 47.2
}, - "temporal_extent": [
- "2018-01-01",
- "2018-02-01"
]
}
}, - "bands": {
- "process_id": "filter_bands",
- "description": "Filter and order the bands. The order is important for the following reduce operation.",
- "arguments": {
- "data": {
- "from_node": "dc"
}, - "bands": [
- "B08",
- "B04",
- "B02"
]
}
}, - "evi": {
- "process_id": "reduce",
- "description": "Compute the EVI. Formula: 2.5 * (NIR - RED) / (1 + NIR + 6*RED + -7.5*BLUE)",
- "arguments": {
- "data": {
- "from_node": "bands"
}, - "dimension": "bands",
- "reducer": {
- "process_graph": {
- "nir": {
- "process_id": "array_element",
- "arguments": {
- "data": {
- "from_parameter": "data"
}, - "index": 0
}
}, - "red": {
- "process_id": "array_element",
- "arguments": {
- "data": {
- "from_parameter": "data"
}, - "index": 1
}
}, - "blue": {
- "process_id": "array_element",
- "arguments": {
- "data": {
- "from_parameter": "data"
}, - "index": 2
}
}, - "sub": {
- "process_id": "subtract",
- "arguments": {
- "data": [
- {
- "from_node": "nir"
}, - {
- "from_node": "red"
}
]
}
}, - "p1": {
- "process_id": "product",
- "arguments": {
- "data": [
- 6,
- {
- "from_node": "red"
}
]
}
}, - "p2": {
- "process_id": "product",
- "arguments": {
- "data": [
- -7.5,
- {
- "from_node": "blue"
}
]
}
}, - "sum": {
- "process_id": "sum",
- "arguments": {
- "data": [
- 1,
- {
- "from_node": "nir"
}, - {
- "from_node": "p1"
}, - {
- "from_node": "p2"
}
]
}
}, - "div": {
- "process_id": "divide",
- "arguments": {
- "data": [
- {
- "from_node": "sub"
}, - {
- "from_node": "sum"
}
]
}
}, - "p3": {
- "process_id": "product",
- "arguments": {
- "data": [
- 2.5,
- {
- "from_node": "div"
}
]
}, - "result": true
}
}
}
}
}, - "mintime": {
- "process_id": "reduce",
- "description": "Compute a minimum time composite by reducing the temporal dimension",
- "arguments": {
- "data": {
- "from_node": "evi"
}, - "dimension": "temporal",
- "reducer": {
- "process_graph": {
- "min": {
- "process_id": "min",
- "arguments": {
- "data": {
- "from_parameter": "data"
}
}, - "result": true
}
}
}
}
}, - "save": {
- "process_id": "save_result",
- "arguments": {
- "data": {
- "from_node": "mintime"
}, - "format": "GTiff"
}, - "result": true
}
}
}, - "status": "running",
- "progress": 75.5,
- "created": "2017-01-01T09:32:12Z",
- "updated": "2017-01-01T09:54:18Z",
- "queued": "2017-01-01T09:34:00Z",
- "started": "2017-01-01T09:36:18Z",
- "unpublished": "2018-01-01T09:54:18Z",
- "plan": "free",
- "costs": 12.98,
- "budget": 100,
- "usage": {
- "cpu": {
- "value": 40668,
- "unit": "cpu-seconds"
}, - "duration": {
- "value": 2611,
- "unit": "seconds"
}, - "memory": {
- "value": 108138811,
- "unit": "mb-seconds"
}, - "network": {
- "value": 0,
- "unit": "kb"
}, - "storage": {
- "value": 55,
- "unit": "mb"
}
}, - "log_level": "warning",
- "links": [
- {
- "rel": "result",
- "type": "application/json",
- "title": "Batch Job Results",
}, - {
- "rel": "result",
- "type": "application/json",
- "title": "Batch Job Logs",
}
]
}Delete a batch job
Deletes all data related to a given batch job. Computations are stopped and computed results are deleted. This job will not generate additional costs for processing.
Authorizations:
path Parameters
| job_id required | string (job_id) ^[\w\-\.~]+$ Example: a3cca2b2aa1e3b5b Identifier of the batch job. |
Responses
Response samples
- 4XX
- 5XX
{- "id": "550e8400-e29b-11d4-a716-446655440000",
- "code": "SampleError",
- "message": "Parameter 'sample' is missing.",
}Get an estimate for a batch job
Calculates an estimate for a batch job. Back-ends can decide to either calculate the duration, the costs, the size or a combination of them.
Back-end providers MAY specify an expiry time for the estimate. Starting to process data afterwards MAY be charged at a higher cost. Costs do often not include download costs. Whether download costs are included or not can be indicated explicitly with the downloads_included flag.
The estimate SHOULD be the upper limit of the costs, but back-end are free to use the field according to their terms of service.
For some batch jobs it is not (easily) possible to estimate the costs reliably, e.g. if a UDF or ML model is part of the process. In this case, the server SHOULD return a EstimateComplexity error with HTTP status code 500.
Authorizations:
path Parameters
| job_id required | string (job_id) ^[\w\-\.~]+$ Example: a3cca2b2aa1e3b5b Identifier of the batch job. |
Responses
Response Schema: application/json
| costs required | number or null (money) >= 0 Default: null An amount of money or credits. The value MUST be specified in the currency the back-end is working with. The currency can be retrieved by calling |
| duration | string Estimated duration for the operation. Duration MUST be specified as an ISO 8601 duration. |
| size | integer Estimated required storage capacity, i.e. the size of the generated files. Size MUST be specified in bytes. |
| downloads_included | integer or null Default: null Specifies how many full downloads of the processed data are included in the estimate. Set to |
| expires | string <date-time> Time until which the estimate is valid, formatted as a RFC 3339 date-time. |
Response samples
- 200
- 4XX
- 5XX
{- "costs": 12.98,
- "duration": "P1Y2M10DT2H30M",
- "size": 157286400,
- "downloads_included": 5,
- "expires": "2020-11-01T00:00:00Z"
}Logs for a batch job
Lists log entries for the batch job, usually for debugging purposes.
Back-ends can log any information that may be relevant for a user
at any stage (status) of the batch job.
Users can log information during data processing using respective
processes such as inspect.
If requested consecutively, it is RECOMMENDED that clients use the offset parameter to get only the entries they have not received yet.
While pagination itself is OPTIONAL, the offset parameter is REQUIRED
to be implemented by back-ends.
Authorizations:
path Parameters
| job_id required | string (job_id) ^[\w\-\.~]+$ Example: a3cca2b2aa1e3b5b Identifier of the batch job. |
query Parameters
| offset | string Example: offset=log1234 The last identifier (property |
| level | string Default: "debug" Enum: "error" "warning" "info" "debug" Example: level=error The minimum severity level for log entries that the back-end returns. The order of the levels is as follows (from low to high severity): The default minimum log level is |
| limit | integer >= 1 Example: limit=10 This parameter enables pagination for the endpoint and specifies the maximum number of
elements that arrays in the top-level object (e.g. collections, processes, batch jobs,
secondary services, log entries, etc.) are allowed to contain.
The Pagination is OPTIONAL: back-ends or clients may not support it. Therefore, it MUST be implemented in a way that clients not supporting pagination get all resources regardless. Back-ends not supporting pagination MUST return all resources. If the response is paginated, the |
Responses
Response Schema: application/json
| level | string Default: "debug" Enum: "error" "warning" "info" "debug" The minimum severity level for log entries that the back-end returns.
This property MUST reflect the effective lowest
The order of the levels is as follows (from low to high severity): |
required | Array of objects (Log Entry) A chronological list of logs. |
required | Array of objects (links_pagination) Links related to this list of resources, for example links for pagination or alternative formats such as a human-readable HTML version. The links array MUST NOT be paginated. If pagination is implemented, the following
For additional relation types see also the lists of common relation types in openEO. |
Response samples
- 200
- 4XX
- 5XX
{- "level": "error",
- "logs": [
- {
- "id": "1",
- "code": "SampleError",
- "level": "error",
- "message": "Can not load the UDF file from the URL `https://openeo.example/invalid/file.txt`. Server responded with error 404.",
- "time": "2019-08-24T14:15:22Z",
- "data": null,
- "path": [
- {
- "node_id": "runudf1",
- "process_id": "ndvi",
- "namespace": null,
- "parameter": "udf"
}
], - "usage": {
- "cpu": {
- "value": 40668,
- "unit": "cpu-seconds"
}, - "duration": {
- "value": 2611,
- "unit": "seconds"
}, - "memory": {
- "value": 108138811,
- "unit": "mb-seconds"
}, - "network": {
- "value": 0,
- "unit": "kb"
}, - "storage": {
- "value": 55,
- "unit": "mb"
}
}, - "stacktrace": "string",
}
], - "links": [
]
}List batch job results
Lists signed URLs pointing to the processed files, usually after the batch job
has finished. Back-ends may also point to intermediate results after the
job has stopped due to an error or if the partial parameter has been set.
The response includes additional metadata. It is a valid
STAC Item
(if it has spatial and temporal references included) or a valid
STAC Collection
(supported since openEO API version 1.1.0).
The assets to download are in both cases available in the property assets
and have the same structure. Additional metadata is not strictly required
to download the files, but are helpful for users to understand the data.
STAC Collections can either (1) add all assets as collection-level assets or
(2) link to STAC Catalogs and STAC Items with signed URLs, which will provide a full
STAC catalog structure a client has to go through. Option 2 is overall the better
architectural choice and allows a fine-grained description of the processed data,
but it is not compliant with previous versions of the openEO API.
To maintain backward compatibility, it is REQUIRED to still copy
all assets in the STAC catalog structure into the collection-level assets.
This requirement is planned to be removed in openEO API version 2.0.0.
A client can enforce that the server returns a GeoJSON through content negotiation
with the media type application/geo+json, but the results may not contain very
meaningful metadata aside from the assets.
Clients are RECOMMENDED to store this response and all potential sub-catalogs and items with the assets so that the downloaded data is then a self-contained STAC catalog user could publish easily with all the data and metadata.
URL signing is a way to protect files from unauthorized access with a
key in the URL instead of HTTP header based authorization. The URL
signing key is similar to a password and its inclusion in the URL allows
to download files using simple GET requests supported by a wide range of
programs, e.g. web browsers or download managers. Back-ends are
responsible to generate the URL signing keys and to manage their
appropriate expiration. The back-end MAY indicate an expiration time by
setting the expires property in the reponse. Requesting this endpoint
SHOULD always return non-expired URLs. Signed URLs that were generated
for a previous request and already expired SHOULD NOT be reused,
but regenerated with new expiration time.
Signed URLs that expired MAY return the openEO error ResultLinkExpired.
Adding a link with relation type canonical to the STAC Item or STAC Collection
is STRONGLY RECOMMENDED (see the links property for details).
If processing has not finished yet and the partial parameter is not set to true
requests to this endpoint MUST be rejected with openEO error JobNotFinished.
Authorizations:
path Parameters
| job_id required | string (job_id) ^[\w\-\.~]+$ Example: a3cca2b2aa1e3b5b Identifier of the batch job. |
query Parameters
| partial | boolean Default: false If set to |
Responses
| OpenEO-Costs | number or null (money) >= 0 Default: null Example: "12.98" Specifies the costs for fully downloading the data once, i.e. this header MAY change in subsequent calls. It MUST be set to |
Response Schema:
| stac_version required | string (stac_version) ^(0\.9.\d+|1\.\d+.\d+) The version of the STAC specification, which MAY not be equal to the STAC API version. The openEO API allows for the STAC versions 1.x.x (RECOMMENDED) and 0.9.x (DEPRECATED). |
Array of Reference to a JSON Schema (string) or Reference to a core extension (STAC < 1.0.0-rc.1 only, DEPRECATED) (string) (stac_extensions) unique A list of implemented STAC extensions. The list contains URLs to the JSON Schema files it can be validated against. | |
| id required | string (job_id) ^[\w\-\.~]+$ Per-back-end unique identifier of the batch job, generated by the back-end during creation. MUST match the specified pattern. |
| type required | string Value: "Feature" The GeoJSON type that applies to this metadata document, which MUST always be a "Feature" according to the STAC specification. This type does not describe the spatial data type of the assets. |
Array of 4 elements (numbers) or Array of 6 elements (numbers) (bbox) Each bounding box is provided as four or six numbers, depending on whether the coordinate reference system includes a vertical axis (height or depth):
The coordinate reference system of the values is WGS 84 longitude/latitude (http://www.opengis.net/def/crs/OGC/1.3/CRS84). For WGS 84 longitude/latitude the values are in most cases the sequence of minimum longitude, minimum latitude, maximum longitude and maximum latitude. However, in cases where the box spans the antimeridian the first value (west-most box edge) is larger than the third value (east-most box edge). If the vertical axis is included, the third and the sixth number are the bottom and the top of the 3-dimensional bounding box. | |
required | object or null (GeoJSON Geometry) Defines the full footprint of the asset represented by this item as GeoJSON Geometry. Results without a known location can set this value to |
required | object (Item Properties) MAY contain additional properties other than the required property |
required | object (Assets) Dictionary of asset objects for data that can be downloaded, each with a unique key. The keys MAY be used by clients as file names. |
required | Array of objects (Link) Links related to this batch job result, e.g. a link to an invoice, additional log files or external documentation. The links MUST NOT contain links to the processed and
downloadable data. Instead specify these in the It is strongly recommended to add a link with relation type
For relation types see the lists of common relation types in openEO. |
Response samples
- 200
- 424
- 4XX
- 5XX
{- "stac_version": "1.1.0",
- "id": "a3cca2b2aa1e3b5b",
- "type": "Feature",
- "bbox": [
- -180,
- -90,
- 180,
- 90
], - "geometry": {
- "type": "Polygon",
- "coordinates": [
- [
- [
- -180,
- -90
], - [
- 180,
- -90
], - [
- 180,
- 90
], - [
- -180,
- 90
], - [
- -180,
- -90
]
]
]
}, - "properties": {
- "datetime": "2019-08-24T14:15:22Z",
- "start_datetime": "2019-08-24T14:15:22Z",
- "end_datetime": "2019-08-24T14:15:22Z",
- "title": "NDVI based on Sentinel-2",
- "description": "Deriving minimum NDVI measurements over pixel time series of Sentinel-2",
- "license": "Apache-2.0",
- "providers": [
- {
- "name": "Example Cloud Corp.",
- "description": "No further processing applied.",
- "roles": [
- "producer",
- "licensor",
- "host"
],
}
], - "created": "2017-01-01T09:32:12Z",
- "updated": "2017-01-01T09:54:18Z",
- "queued": "2017-01-01T09:34:00Z",
- "started": "2017-01-01T09:36:18Z",
- "expires": "2017-02-01T09:54:18Z",
- "unpublished": "2018-01-01T09:54:18Z",
- "openeo:status": "running"
}, - "assets": {
- "preview.png": {
- "type": "image/png",
- "title": "Thumbnail",
- "roles": [
- "thumbnail"
]
}, - "process.json": {
- "type": "application/json",
- "title": "Original Process",
- "roles": [
- "process",
- "reproduction"
]
}, - "1.tif": {
- "type": "image/tiff; application=geotiff",
- "title": "Band 1",
- "roles": [
- "data"
]
}, - "2.tif": {
- "type": "image/tiff; application=geotiff",
- "title": "Band 2",
- "roles": [
- "data"
]
}, - "inspire.xml": {
- "type": "application/xml",
- "title": "INSPIRE metadata",
- "description": "INSPIRE compliant XML metadata",
- "roles": [
- "metadata"
]
}
}, - "links": [
- {
- "rel": "canonical",
- "type": "application/geo+json",
}
]
}Start processing a batch job
Adds a batch job to the processing queue to compute the results.
The result will be stored in the format specified in the process.
To specify the format use a process such as save_result.
The job status is set to queued, if processing does not start
instantly. The same applies if the job status is canceled, finished,
or error, which restarts the job and discards previous results if the
back-end does not reject the request with an error.
Clients SHOULD warn users and ask for confirmation if results may get
discarded.
- Once the processing starts the status is set to
running. - Once the data is available to download the status is set to
finished. - Whenever an error occurs during processing, the status MUST be set to
error.
This endpoint has no effect if the job status is already queued or
running. In particular, it does not restart a running job. To restart
a queued or running job, processing MUST have been canceled.
Back-ends SHOULD reject queueing jobs with openEO error PaymentRequired,
if the back-end is able to detect that the budget is too low to fully
process the request. Alternatively, back-ends MAY provide partial results
once reaching the budget. If none of the alternatives is feasible, the
results are discarded. Thus, client SHOULD warn users that reaching the
budget may lead to partial or no results at all.
Authorizations:
path Parameters
| job_id required | string (job_id) ^[\w\-\.~]+$ Example: a3cca2b2aa1e3b5b Identifier of the batch job. |
Responses
Response samples
- 4XX
- 5XX
{- "id": "550e8400-e29b-11d4-a716-446655440000",
- "code": "SampleError",
- "message": "Parameter 'sample' is missing.",
}Cancel processing a batch job
Cancels all related computations for this job at the back-end. It will stop generating additional costs for processing.
A subset of processed results may be available for downloading depending on the state of the job at the time it was canceled.
Results MUST NOT be deleted until the job processing is started again or
the job is completely deleted through a request to
DELETE /jobs/{job_id}.
This endpoint only has an effect if the job status is queued or
running.
The job status is set to canceled if the status was running
beforehand and partial or preliminary results are available to be
downloaded. Otherwise the status is set to created.
Authorizations:
path Parameters
| job_id required | string (job_id) ^[\w\-\.~]+$ Example: a3cca2b2aa1e3b5b Identifier of the batch job. |
Responses
Response samples
- 4XX
- 5XX
{- "id": "550e8400-e29b-11d4-a716-446655440000",
- "code": "SampleError",
- "message": "Parameter 'sample' is missing.",
}Supported secondary web service protocols
Lists supported secondary web service protocols such as OGC WMS, OGC WCS, OGC API - Features or XYZ tiles. The response is an object of all available secondary web service protocols with their supported configuration settings and expected process parameters.
- The configuration settings for the service SHOULD be defined upon creation of a service and the service will be set up accordingly.
- The process parameters SHOULD be referenced (with a
from_parameterreference) in the user-defined process that is used to compute web service results. The appropriate arguments MUST be provided to the user-defined process, usually at runtime from the context of the web service. For example, a map service such as a WMS would need to inject the spatial extent into the user-defined process so that the back-end can compute the corresponding tile correctly.
To improve interoperability between back-ends common names for the services SHOULD be used, e.g. the abbreviations used in the official OGC Schema Repository for the respective services.
Service names MUST be accepted in a case insensitive manner throughout the API.
Authorizations:
Responses
Response Schema: application/json
additional property | object (Service Type) |
Response samples
- 200
- 4XX
- 5XX
{- "WMS": {
- "title": "OGC Web Map Service",
- "configuration": {
- "version": {
- "type": "string",
- "description": "The WMS version offered to consumers of the service.",
- "default": "1.3.0",
- "enum": [
- "1.1.1",
- "1.3.0"
]
}
}, - "process_parameters": [
- {
- "name": "layer",
- "description": "The layer name.",
- "schema": {
- "type": "string"
}, - "default": "roads"
}, - {
- "name": "spatial_extent",
- "description": "A bounding box in WGS84.",
- "schema": {
- "type": "object",
- "required": [
- "west",
- "south",
- "east",
- "north"
], - "properties": {
- "west": {
- "description": "West (lower left corner, coordinate axis 1).",
- "type": "number"
}, - "south": {
- "description": "South (lower left corner, coordinate axis 2).",
- "type": "number"
}, - "east": {
- "description": "East (upper right corner, coordinate axis 1).",
- "type": "number"
}, - "north": {
- "description": "North (upper right corner, coordinate axis 2).",
- "type": "number"
}
}
}
}
], - "links": [
- {
- "rel": "about",
- "title": "OGC Web Map Service Standard"
}
]
}, - "OGCAPI-FEATURES": {
- "title": "OGC API - Features",
- "description": "Exposes a OGC API - Features in version 1.0 of the specification (successor of OGC WFS 3.0).",
- "configuration": {
- "title": {
- "type": "string",
- "description": "The title for the OGC API - Features landing page"
}, - "description": {
- "type": "string",
- "description": "The description for the OGC API - Features landing page"
}, - "conformsTo": {
- "type": "array",
- "description": "The OGC API - Features conformance classes to enable for this service.\n\n`http://www.opengis.net/spec/ogcapi-features-1/1.0/conf/core` is always enabled.",
}
}, - "process_parameters": [ ],
- "links": [
- {
- "rel": "about",
- "title": "OGC Web Feature Service Standard"
}
]
}
}List all web services
Lists all secondary web services submitted by a user.
It is strongly RECOMMENDED to keep the response size small by omitting
all optional non-scalar values (i.e. arrays and objects) from objects in services
(i.e. the process, configuration and attributes properties).
To get the full metadata for a secondary web service clients MUST
request GET /services/{service_id}.
Authorizations:
query Parameters
| limit | integer >= 1 Example: limit=10 This parameter enables pagination for the endpoint and specifies the maximum number of
elements that arrays in the top-level object (e.g. collections, processes, batch jobs,
secondary services, log entries, etc.) are allowed to contain.
The Pagination is OPTIONAL: back-ends or clients may not support it. Therefore, it MUST be implemented in a way that clients not supporting pagination get all resources regardless. Back-ends not supporting pagination MUST return all resources. If the response is paginated, the |
Responses
Response Schema: application/json
required | Array of objects (Secondary Web Service) |
required | Array of objects (links_pagination) Links related to this list of resources, for example links for pagination or alternative formats such as a human-readable HTML version. The links array MUST NOT be paginated. If pagination is implemented, the following
For additional relation types see also the lists of common relation types in openEO. |
Response samples
- 200
- 4XX
- 5XX
{- "services": [
- {
- "id": "wms-a3cca9",
- "title": "NDVI based on Sentinel-2",
- "description": "Deriving minimum NDVI measurements over pixel time series of Sentinel-2",
- "type": "wms",
- "enabled": true,
- "process": {
- "id": "ndvi",
- "summary": "string",
- "description": "string",
- "parameters": [
- {
- "schema": {
- "subtype": "string",
- "deprecated": false,
- "type": "string",
- "enum": [
- "a",
- "b"
]
}, - "name": "string",
- "description": "string",
- "optional": false,
- "deprecated": false,
- "experimental": false,
- "default": null
}
], - "returns": {
- "description": "string",
- "schema": {
- "subtype": "string",
- "deprecated": false,
- "type": "string",
- "enum": [
- "a",
- "b"
]
}
}, - "categories": [
- "string"
], - "deprecated": false,
- "experimental": false,
- "exceptions": {
- "Error Code1": {
- "description": "string",
- "message": "The value specified for the process argument '{argument}' in process '{process}' is invalid: {reason}",
- "http": 400
}, - "Error Code2": {
- "description": "string",
- "message": "The value specified for the process argument '{argument}' in process '{process}' is invalid: {reason}",
- "http": 400
}
}, - "examples": [
- {
- "title": "string",
- "description": "string",
- "arguments": {
- "property1": {
- "from_parameter": null,
- "from_node": null,
- "process_graph": null
}, - "property2": {
- "from_parameter": null,
- "from_node": null,
- "process_graph": null
}
}, - "returns": null
}
], - "links": [
], - "process_graph": {
- "dc": {
- "process_id": "load_collection",
- "arguments": {
- "id": "Sentinel-2",
- "spatial_extent": {
- "west": 16.1,
- "east": 16.6,
- "north": 48.6,
- "south": 47.2
}, - "temporal_extent": [
- "2018-01-01",
- "2018-02-01"
]
}
}, - "bands": {
- "process_id": "filter_bands",
- "description": "Filter and order the bands. The order is important for the following reduce operation.",
- "arguments": {
- "data": {
- "from_node": "dc"
}, - "bands": [
- "B08",
- "B04",
- "B02"
]
}
}, - "evi": {
- "process_id": "reduce",
- "description": "Compute the EVI. Formula: 2.5 * (NIR - RED) / (1 + NIR + 6*RED + -7.5*BLUE)",
- "arguments": {
- "data": {
- "from_node": "bands"
}, - "dimension": "bands",
- "reducer": {
- "process_graph": {
- "nir": {
- "process_id": "array_element",
- "arguments": {
- "data": {
- "from_parameter": "data"
}, - "index": 0
}
}, - "red": {
- "process_id": "array_element",
- "arguments": {
- "data": {
- "from_parameter": "data"
}, - "index": 1
}
}, - "blue": {
- "process_id": "array_element",
- "arguments": {
- "data": {
- "from_parameter": "data"
}, - "index": 2
}
}, - "sub": {
- "process_id": "subtract",
- "arguments": {
- "data": [
- {
- "from_node": "nir"
}, - {
- "from_node": "red"
}
]
}
}, - "p1": {
- "process_id": "product",
- "arguments": {
- "data": [
- 6,
- {
- "from_node": "red"
}
]
}
}, - "p2": {
- "process_id": "product",
- "arguments": {
- "data": [
- -7.5,
- {
- "from_node": "blue"
}
]
}
}, - "sum": {
- "process_id": "sum",
- "arguments": {
- "data": [
- 1,
- {
- "from_node": "nir"
}, - {
- "from_node": "p1"
}, - {
- "from_node": "p2"
}
]
}
}, - "div": {
- "process_id": "divide",
- "arguments": {
- "data": [
- {
- "from_node": "sub"
}, - {
- "from_node": "sum"
}
]
}
}, - "p3": {
- "process_id": "product",
- "arguments": {
- "data": [
- 2.5,
- {
- "from_node": "div"
}
]
}, - "result": true
}
}
}
}
}, - "mintime": {
- "process_id": "reduce",
- "description": "Compute a minimum time composite by reducing the temporal dimension",
- "arguments": {
- "data": {
- "from_node": "evi"
}, - "dimension": "temporal",
- "reducer": {
- "process_graph": {
- "min": {
- "process_id": "min",
- "arguments": {
- "data": {
- "from_parameter": "data"
}
}, - "result": true
}
}
}
}
}, - "save": {
- "process_id": "save_result",
- "arguments": {
- "data": {
- "from_node": "mintime"
}, - "format": "GTiff"
}, - "result": true
}
}
}, - "configuration": {
- "version": "1.3.0"
}, - "attributes": {
- "layers": [
- "ndvi",
- "evi"
]
}, - "created": "2017-01-01T09:32:12Z",
- "plan": "free",
- "costs": 12.98,
- "budget": 100,
- "usage": {
- "cpu": {
- "value": 40668,
- "unit": "cpu-seconds"
}, - "duration": {
- "value": 2611,
- "unit": "seconds"
}, - "memory": {
- "value": 108138811,
- "unit": "mb-seconds"
}, - "network": {
- "value": 0,
- "unit": "kb"
}, - "storage": {
- "value": 55,
- "unit": "mb"
}
}, - "log_level": "warning"
}
], - "links": [
]
}Publish a new service
Creates a new secondary web service such as a OGC WMS, OGC WCS, OGC API - Features or XYZ tiles.
The secondary web service SHOULD process the underlying
data on demand, based on process parameters provided to the
user-defined process (through from_parameter references) at run-time,
for example for the spatial/temporal extent, resolution, etc.
The available process parameters are specified per
service type at GET /service_types.
Note: Costs incurred by shared secondary web services are usually paid by the owner, but this depends on the service type and whether it supports charging fees or not.
Authorizations:
Request Body schema: application/jsonrequired
The base data required to create the secondary web service.
| title | string or null (eo_title) A short description to easily distinguish entities. |
| description | string or null <commonmark> (eo_description) Detailed multi-line description to explain the entity. CommonMark 0.29 syntax MAY be used for rich text representation. |
required | object (Process Graph with metadata) A process graph, optionally enriched with process metadata. |
| type required | string (service_type) Definition of the service type to access result data. All available service types can be retrieved via |
| enabled | boolean Default: true Describes whether a secondary web service is responding to requests (true) or not (false). Disabled services do not produce any costs. |
| configuration | object (Service Configuration) Map of configuration settings, i.e. the setting names supported by the secondary web service combined with actual values. See |
| plan | string or null (billing_plan_null_default) Default: null The billing plan to process and charge the job or service with. Billing plans MUST be accepted in a case insensitive manner. Back-ends MUST resolve the billing plan in the following way:
The resolved plan MUST be persisted permanently, regardless of any
changes to the exposed billing plans in Billing plans not on the list of available plans MUST be rejected with
openEO error |
| budget | number or null (budget) >= 0 Default: null Maximum amount of costs the request is allowed to produce.
The value MUST be specified in the currency of the back-end.
No limits apply, if the value is |
| log_level | string (min_log_level_default) Default: "info" Enum: "error" "warning" "info" "debug" The minimum severity level for log entries that the back-end stores for the processing request. The order of the levels is as follows (from low to high severity): The default minimum log level is |
| property name* additional property | any Additional back-end specific properties are allowed. |
Responses
| Location required | string <uri> Example: "https://openeo.example/api/v1/services/123" Absolute URL to the newly created service. The URL points to the metadata endpoint
|
| OpenEO-Identifier required | string (service_id) ^[\w\-\.~]+$ Example: "wms-a3cca9" A per-back-end unique identifier of the secondary web service, generated by the back-end during creation. MUST match the specified pattern. |
Request samples
- Payload
{- "title": "NDVI based on Sentinel-2",
- "description": "Deriving minimum NDVI measurements over pixel time series of Sentinel-2",
- "process": {
- "id": "ndvi",
- "summary": "string",
- "description": "string",
- "parameters": [
- {
- "schema": {
- "subtype": "string",
- "deprecated": false,
- "type": "string",
- "enum": [
- "a",
- "b"
]
}, - "name": "string",
- "description": "string",
- "optional": false,
- "deprecated": false,
- "experimental": false,
- "default": null
}
], - "returns": {
- "description": "string",
- "schema": {
- "subtype": "string",
- "deprecated": false,
- "type": "string",
- "enum": [
- "a",
- "b"
]
}
}, - "categories": [
- "string"
], - "deprecated": false,
- "experimental": false,
- "exceptions": {
- "Error Code1": {
- "description": "string",
- "message": "The value specified for the process argument '{argument}' in process '{process}' is invalid: {reason}",
- "http": 400
}, - "Error Code2": {
- "description": "string",
- "message": "The value specified for the process argument '{argument}' in process '{process}' is invalid: {reason}",
- "http": 400
}
}, - "examples": [
- {
- "title": "string",
- "description": "string",
- "arguments": {
- "property1": {
- "from_parameter": null,
- "from_node": null,
- "process_graph": null
}, - "property2": {
- "from_parameter": null,
- "from_node": null,
- "process_graph": null
}
}, - "returns": null
}
], - "links": [
], - "process_graph": {
- "dc": {
- "process_id": "load_collection",
- "arguments": {
- "id": "Sentinel-2",
- "spatial_extent": {
- "west": 16.1,
- "east": 16.6,
- "north": 48.6,
- "south": 47.2
}, - "temporal_extent": [
- "2018-01-01",
- "2018-02-01"
]
}
}, - "bands": {
- "process_id": "filter_bands",
- "description": "Filter and order the bands. The order is important for the following reduce operation.",
- "arguments": {
- "data": {
- "from_node": "dc"
}, - "bands": [
- "B08",
- "B04",
- "B02"
]
}
}, - "evi": {
- "process_id": "reduce",
- "description": "Compute the EVI. Formula: 2.5 * (NIR - RED) / (1 + NIR + 6*RED + -7.5*BLUE)",
- "arguments": {
- "data": {
- "from_node": "bands"
}, - "dimension": "bands",
- "reducer": {
- "process_graph": {
- "nir": {
- "process_id": "array_element",
- "arguments": {
- "data": {
- "from_parameter": "data"
}, - "index": 0
}
}, - "red": {
- "process_id": "array_element",
- "arguments": {
- "data": {
- "from_parameter": "data"
}, - "index": 1
}
}, - "blue": {
- "process_id": "array_element",
- "arguments": {
- "data": {
- "from_parameter": "data"
}, - "index": 2
}
}, - "sub": {
- "process_id": "subtract",
- "arguments": {
- "data": [
- {
- "from_node": "nir"
}, - {
- "from_node": "red"
}
]
}
}, - "p1": {
- "process_id": "product",
- "arguments": {
- "data": [
- 6,
- {
- "from_node": "red"
}
]
}
}, - "p2": {
- "process_id": "product",
- "arguments": {
- "data": [
- -7.5,
- {
- "from_node": "blue"
}
]
}
}, - "sum": {
- "process_id": "sum",
- "arguments": {
- "data": [
- 1,
- {
- "from_node": "nir"
}, - {
- "from_node": "p1"
}, - {
- "from_node": "p2"
}
]
}
}, - "div": {
- "process_id": "divide",
- "arguments": {
- "data": [
- {
- "from_node": "sub"
}, - {
- "from_node": "sum"
}
]
}
}, - "p3": {
- "process_id": "product",
- "arguments": {
- "data": [
- 2.5,
- {
- "from_node": "div"
}
]
}, - "result": true
}
}
}
}
}, - "mintime": {
- "process_id": "reduce",
- "description": "Compute a minimum time composite by reducing the temporal dimension",
- "arguments": {
- "data": {
- "from_node": "evi"
}, - "dimension": "temporal",
- "reducer": {
- "process_graph": {
- "min": {
- "process_id": "min",
- "arguments": {
- "data": {
- "from_parameter": "data"
}
}, - "result": true
}
}
}
}
}, - "save": {
- "process_id": "save_result",
- "arguments": {
- "data": {
- "from_node": "mintime"
}, - "format": "GTiff"
}, - "result": true
}
}
}, - "type": "wms",
- "enabled": true,
- "configuration": {
- "version": "1.3.0"
}, - "plan": "free",
- "budget": 100,
- "log_level": "warning",
- "property1": null,
- "property2": null
}Response samples
- 4XX
- 5XX
{- "id": "550e8400-e29b-11d4-a716-446655440000",
- "code": "SampleError",
- "message": "Parameter 'sample' is missing.",
}Modify a service
Modifies an existing secondary web service at the back-end, but maintains the identifier. Changes can be grouped into a single request.
User MUST create a new service to change the service type.
Authorizations:
path Parameters
| service_id required | string (service_id) ^[\w\-\.~]+$ Example: wms-a3cca9 Identifier of the secondary web service. |
Request Body schema: application/jsonrequired
The data to change for the specified secondary web service.
| title | string or null (eo_title) A short description to easily distinguish entities. |
| description | string or null <commonmark> (eo_description) Detailed multi-line description to explain the entity. CommonMark 0.29 syntax MAY be used for rich text representation. |
object (Process Graph with metadata) A process graph, optionally enriched with process metadata. | |
| enabled | boolean (service_enabled) Describes whether a secondary web service is responding to requests (true) or not (false). Disabled services do not produce any costs. |
| configuration | object (Service Configuration) Map of configuration settings, i.e. the setting names supported by the secondary web service combined with actual values. See |
| plan | string or null (billing_plan_null) The billing plan to process and charge the job or service with. Billing plans MUST be accepted in a case insensitive manner. Back-ends MUST resolve the billing plan in the following way if billing is supported:
Billing plans not on the list of available plans MUST be rejected with
openEO error |
| budget | number or null (budget_update) >= 0 Maximum amount of costs the request is allowed to produce.
The value MUST be specified in the currency of the back-end.
No limits apply, if the value is |
| log_level | string (min_log_level_update) Enum: "error" "warning" "info" "debug" Updates the minimum severity level for log entries that the back-end stores for the processing requests. The back-end does not need to update existing log entries. |
| property name* additional property | any Additional back-end specific properties are allowed. |
Responses
Request samples
- Payload
{- "title": "NDVI based on Sentinel-2",
- "description": "Deriving minimum NDVI measurements over pixel time series of Sentinel-2",
- "process": {
- "id": "ndvi",
- "summary": "string",
- "description": "string",
- "parameters": [
- {
- "schema": {
- "subtype": "string",
- "deprecated": false,
- "type": "string",
- "enum": [
- "a",
- "b"
]
}, - "name": "string",
- "description": "string",
- "optional": false,
- "deprecated": false,
- "experimental": false,
- "default": null
}
], - "returns": {
- "description": "string",
- "schema": {
- "subtype": "string",
- "deprecated": false,
- "type": "string",
- "enum": [
- "a",
- "b"
]
}
}, - "categories": [
- "string"
], - "deprecated": false,
- "experimental": false,
- "exceptions": {
- "Error Code1": {
- "description": "string",
- "message": "The value specified for the process argument '{argument}' in process '{process}' is invalid: {reason}",
- "http": 400
}, - "Error Code2": {
- "description": "string",
- "message": "The value specified for the process argument '{argument}' in process '{process}' is invalid: {reason}",
- "http": 400
}
}, - "examples": [
- {
- "title": "string",
- "description": "string",
- "arguments": {
- "property1": {
- "from_parameter": null,
- "from_node": null,
- "process_graph": null
}, - "property2": {
- "from_parameter": null,
- "from_node": null,
- "process_graph": null
}
}, - "returns": null
}
], - "links": [
], - "process_graph": {
- "dc": {
- "process_id": "load_collection",
- "arguments": {
- "id": "Sentinel-2",
- "spatial_extent": {
- "west": 16.1,
- "east": 16.6,
- "north": 48.6,
- "south": 47.2
}, - "temporal_extent": [
- "2018-01-01",
- "2018-02-01"
]
}
}, - "bands": {
- "process_id": "filter_bands",
- "description": "Filter and order the bands. The order is important for the following reduce operation.",
- "arguments": {
- "data": {
- "from_node": "dc"
}, - "bands": [
- "B08",
- "B04",
- "B02"
]
}
}, - "evi": {
- "process_id": "reduce",
- "description": "Compute the EVI. Formula: 2.5 * (NIR - RED) / (1 + NIR + 6*RED + -7.5*BLUE)",
- "arguments": {
- "data": {
- "from_node": "bands"
}, - "dimension": "bands",
- "reducer": {
- "process_graph": {
- "nir": {
- "process_id": "array_element",
- "arguments": {
- "data": {
- "from_parameter": "data"
}, - "index": 0
}
}, - "red": {
- "process_id": "array_element",
- "arguments": {
- "data": {
- "from_parameter": "data"
}, - "index": 1
}
}, - "blue": {
- "process_id": "array_element",
- "arguments": {
- "data": {
- "from_parameter": "data"
}, - "index": 2
}
}, - "sub": {
- "process_id": "subtract",
- "arguments": {
- "data": [
- {
- "from_node": "nir"
}, - {
- "from_node": "red"
}
]
}
}, - "p1": {
- "process_id": "product",
- "arguments": {
- "data": [
- 6,
- {
- "from_node": "red"
}
]
}
}, - "p2": {
- "process_id": "product",
- "arguments": {
- "data": [
- -7.5,
- {
- "from_node": "blue"
}
]
}
}, - "sum": {
- "process_id": "sum",
- "arguments": {
- "data": [
- 1,
- {
- "from_node": "nir"
}, - {
- "from_node": "p1"
}, - {
- "from_node": "p2"
}
]
}
}, - "div": {
- "process_id": "divide",
- "arguments": {
- "data": [
- {
- "from_node": "sub"
}, - {
- "from_node": "sum"
}
]
}
}, - "p3": {
- "process_id": "product",
- "arguments": {
- "data": [
- 2.5,
- {
- "from_node": "div"
}
]
}, - "result": true
}
}
}
}
}, - "mintime": {
- "process_id": "reduce",
- "description": "Compute a minimum time composite by reducing the temporal dimension",
- "arguments": {
- "data": {
- "from_node": "evi"
}, - "dimension": "temporal",
- "reducer": {
- "process_graph": {
- "min": {
- "process_id": "min",
- "arguments": {
- "data": {
- "from_parameter": "data"
}
}, - "result": true
}
}
}
}
}, - "save": {
- "process_id": "save_result",
- "arguments": {
- "data": {
- "from_node": "mintime"
}, - "format": "GTiff"
}, - "result": true
}
}
}, - "enabled": true,
- "configuration": {
- "version": "1.3.0"
}, - "plan": "free",
- "budget": 100,
- "log_level": "warning",
- "property1": null,
- "property2": null
}Response samples
- 4XX
- 5XX
{- "id": "550e8400-e29b-11d4-a716-446655440000",
- "code": "SampleError",
- "message": "Parameter 'sample' is missing.",
}Full metadata for a service
Lists all information about a secondary web service.
Authorizations:
path Parameters
| service_id required | string (service_id) ^[\w\-\.~]+$ Example: wms-a3cca9 Identifier of the secondary web service. |
Responses
Response Schema: application/json
| id required | string (service_id) ^[\w\-\.~]+$ A per-back-end unique identifier of the secondary web service, generated by the back-end during creation. MUST match the specified pattern. |
| title | string or null (eo_title) A short description to easily distinguish entities. |
| description | string or null <commonmark> (eo_description) Detailed multi-line description to explain the entity. CommonMark 0.29 syntax MAY be used for rich text representation. |
| url required | string <uri> URL at which the secondary web service is accessible. Does not necessarily need to be located within the API. |
| type required | string (service_type) Definition of the service type to access result data. All available service types can be retrieved via |
| enabled required | boolean (service_enabled) Describes whether a secondary web service is responding to requests (true) or not (false). Disabled services do not produce any costs. |
required | object (Process Graph with metadata) A process graph, optionally enriched with process metadata. |
| configuration required | object (Service Configuration) Map of configuration settings, i.e. the setting names supported by the secondary web service combined with actual values. See |
| attributes required | object (Secondary Web Service Attributes) Additional attributes of the secondary web service, e.g. available layers for a WMS instance based on the bands in the underlying GeoTiff. |
| created | string <date-time> (created) Date and time of creation (for batch jobs: the status 'created' was set), formatted as a RFC 3339 date-time. |
| plan | string (billing_plan) The billing plan to process and charge the job or service with. Billing plans MUST be handled in a case insensitive manner. The plans can be retrieved from |
| costs | number or null (money) >= 0 Default: null An amount of money or credits. The value MUST be specified in the currency the back-end is working with. The currency can be retrieved by calling |
| budget | number or null (budget) >= 0 Default: null Maximum amount of costs the request is allowed to produce.
The value MUST be specified in the currency of the back-end.
No limits apply, if the value is |
object (Resource usage metrics) Metrics about the resource usage of the secondary web service. Back-ends are not expected to update the metrics in real-time.
For detailed usage metrics for individual processing steps, metrics
can be added to the logs (e.g. | |
| log_level | string (min_log_level_default) Default: "info" Enum: "error" "warning" "info" "debug" The minimum severity level for log entries that the back-end stores for the processing request. The order of the levels is as follows (from low to high severity): The default minimum log level is |
| property name* additional property | any You can list additional back-end specific properties here. |
Response samples
- 200
- 4XX
- 5XX
{- "property1": null,
- "property2": null,
- "id": "wms-a3cca9",
- "title": "NDVI based on Sentinel-2",
- "description": "Deriving minimum NDVI measurements over pixel time series of Sentinel-2",
- "type": "wms",
- "enabled": true,
- "process": {
- "id": "ndvi",
- "summary": "string",
- "description": "string",
- "parameters": [
- {
- "schema": {
- "subtype": "string",
- "deprecated": false,
- "type": "string",
- "enum": [
- "a",
- "b"
]
}, - "name": "string",
- "description": "string",
- "optional": false,
- "deprecated": false,
- "experimental": false,
- "default": null
}
], - "returns": {
- "description": "string",
- "schema": {
- "subtype": "string",
- "deprecated": false,
- "type": "string",
- "enum": [
- "a",
- "b"
]
}
}, - "categories": [
- "string"
], - "deprecated": false,
- "experimental": false,
- "exceptions": {
- "Error Code1": {
- "description": "string",
- "message": "The value specified for the process argument '{argument}' in process '{process}' is invalid: {reason}",
- "http": 400
}, - "Error Code2": {
- "description": "string",
- "message": "The value specified for the process argument '{argument}' in process '{process}' is invalid: {reason}",
- "http": 400
}
}, - "examples": [
- {
- "title": "string",
- "description": "string",
- "arguments": {
- "property1": {
- "from_parameter": null,
- "from_node": null,
- "process_graph": null
}, - "property2": {
- "from_parameter": null,
- "from_node": null,
- "process_graph": null
}
}, - "returns": null
}
], - "links": [
], - "process_graph": {
- "dc": {
- "process_id": "load_collection",
- "arguments": {
- "id": "Sentinel-2",
- "spatial_extent": {
- "west": 16.1,
- "east": 16.6,
- "north": 48.6,
- "south": 47.2
}, - "temporal_extent": [
- "2018-01-01",
- "2018-02-01"
]
}
}, - "bands": {
- "process_id": "filter_bands",
- "description": "Filter and order the bands. The order is important for the following reduce operation.",
- "arguments": {
- "data": {
- "from_node": "dc"
}, - "bands": [
- "B08",
- "B04",
- "B02"
]
}
}, - "evi": {
- "process_id": "reduce",
- "description": "Compute the EVI. Formula: 2.5 * (NIR - RED) / (1 + NIR + 6*RED + -7.5*BLUE)",
- "arguments": {
- "data": {
- "from_node": "bands"
}, - "dimension": "bands",
- "reducer": {
- "process_graph": {
- "nir": {
- "process_id": "array_element",
- "arguments": {
- "data": {
- "from_parameter": "data"
}, - "index": 0
}
}, - "red": {
- "process_id": "array_element",
- "arguments": {
- "data": {
- "from_parameter": "data"
}, - "index": 1
}
}, - "blue": {
- "process_id": "array_element",
- "arguments": {
- "data": {
- "from_parameter": "data"
}, - "index": 2
}
}, - "sub": {
- "process_id": "subtract",
- "arguments": {
- "data": [
- {
- "from_node": "nir"
}, - {
- "from_node": "red"
}
]
}
}, - "p1": {
- "process_id": "product",
- "arguments": {
- "data": [
- 6,
- {
- "from_node": "red"
}
]
}
}, - "p2": {
- "process_id": "product",
- "arguments": {
- "data": [
- -7.5,
- {
- "from_node": "blue"
}
]
}
}, - "sum": {
- "process_id": "sum",
- "arguments": {
- "data": [
- 1,
- {
- "from_node": "nir"
}, - {
- "from_node": "p1"
}, - {
- "from_node": "p2"
}
]
}
}, - "div": {
- "process_id": "divide",
- "arguments": {
- "data": [
- {
- "from_node": "sub"
}, - {
- "from_node": "sum"
}
]
}
}, - "p3": {
- "process_id": "product",
- "arguments": {
- "data": [
- 2.5,
- {
- "from_node": "div"
}
]
}, - "result": true
}
}
}
}
}, - "mintime": {
- "process_id": "reduce",
- "description": "Compute a minimum time composite by reducing the temporal dimension",
- "arguments": {
- "data": {
- "from_node": "evi"
}, - "dimension": "temporal",
- "reducer": {
- "process_graph": {
- "min": {
- "process_id": "min",
- "arguments": {
- "data": {
- "from_parameter": "data"
}
}, - "result": true
}
}
}
}
}, - "save": {
- "process_id": "save_result",
- "arguments": {
- "data": {
- "from_node": "mintime"
}, - "format": "GTiff"
}, - "result": true
}
}
}, - "configuration": {
- "version": "1.3.0"
}, - "attributes": {
- "layers": [
- "ndvi",
- "evi"
]
}, - "created": "2017-01-01T09:32:12Z",
- "plan": "free",
- "costs": 12.98,
- "budget": 100,
- "usage": {
- "cpu": {
- "value": 40668,
- "unit": "cpu-seconds"
}, - "duration": {
- "value": 2611,
- "unit": "seconds"
}, - "memory": {
- "value": 108138811,
- "unit": "mb-seconds"
}, - "network": {
- "value": 0,
- "unit": "kb"
}, - "storage": {
- "value": 55,
- "unit": "mb"
}
}, - "log_level": "warning"
}Delete a service
Deletes all data related to this secondary web service. Computations are stopped, computed results are deleted, and access to this service is no longer possible. This service will not generate additional costs.
Authorizations:
path Parameters
| service_id required | string (service_id) ^[\w\-\.~]+$ Example: wms-a3cca9 Identifier of the secondary web service. |
Responses
Response samples
- 4XX
- 5XX
{- "id": "550e8400-e29b-11d4-a716-446655440000",
- "code": "SampleError",
- "message": "Parameter 'sample' is missing.",
}Logs for a secondary service
Lists log entries for the secondary service, usually for debugging purposes.
Back-ends can log any information that may be relevant for a user. Users can log information during data processing using respective processes such as inspect.
If requested consecutively while the secondary service is enabled, it is RECOMMENDED that clients use the offset parameter to get only the entries they have not received yet.
While pagination itself is OPTIONAL, the offset parameter is REQUIRED to be implemented by back-ends.
Authorizations:
path Parameters
| service_id required | string (service_id) ^[\w\-\.~]+$ Example: wms-a3cca9 Identifier of the secondary web service. |
query Parameters
| offset | string Example: offset=log1234 The last identifier (property |
| level | string Default: "debug" Enum: "error" "warning" "info" "debug" Example: level=error The minimum severity level for log entries that the back-end returns. The order of the levels is as follows (from low to high severity): The default minimum log level is |
| limit | integer >= 1 Example: limit=10 This parameter enables pagination for the endpoint and specifies the maximum number of
elements that arrays in the top-level object (e.g. collections, processes, batch jobs,
secondary services, log entries, etc.) are allowed to contain.
The Pagination is OPTIONAL: back-ends or clients may not support it. Therefore, it MUST be implemented in a way that clients not supporting pagination get all resources regardless. Back-ends not supporting pagination MUST return all resources. If the response is paginated, the |
Responses
Response Schema: application/json
| level | string Default: "debug" Enum: "error" "warning" "info" "debug" The minimum severity level for log entries that the back-end returns.
This property MUST reflect the effective lowest
The order of the levels is as follows (from low to high severity): |
required | Array of objects (Log Entry) A chronological list of logs. |
required | Array of objects (links_pagination) Links related to this list of resources, for example links for pagination or alternative formats such as a human-readable HTML version. The links array MUST NOT be paginated. If pagination is implemented, the following
For additional relation types see also the lists of common relation types in openEO. |
Response samples
- 200
- 4XX
- 5XX
{- "level": "error",
- "logs": [
- {
- "id": "1",
- "code": "SampleError",
- "level": "error",
- "message": "Can not load the UDF file from the URL `https://openeo.example/invalid/file.txt`. Server responded with error 404.",
- "time": "2019-08-24T14:15:22Z",
- "data": null,
- "path": [
- {
- "node_id": "runudf1",
- "process_id": "ndvi",
- "namespace": null,
- "parameter": "udf"
}
], - "usage": {
- "cpu": {
- "value": 40668,
- "unit": "cpu-seconds"
}, - "duration": {
- "value": 2611,
- "unit": "seconds"
}, - "memory": {
- "value": 108138811,
- "unit": "mb-seconds"
}, - "network": {
- "value": 0,
- "unit": "kb"
}, - "storage": {
- "value": 55,
- "unit": "mb"
}
}, - "stacktrace": "string",
}
], - "links": [
]
}List all files in the workspace
Lists all user-uploaded files that are stored at the back-end.
Authorizations:
query Parameters
| limit | integer >= 1 Example: limit=10 This parameter enables pagination for the endpoint and specifies the maximum number of
elements that arrays in the top-level object (e.g. collections, processes, batch jobs,
secondary services, log entries, etc.) are allowed to contain.
The Pagination is OPTIONAL: back-ends or clients may not support it. Therefore, it MUST be implemented in a way that clients not supporting pagination get all resources regardless. Back-ends not supporting pagination MUST return all resources. If the response is paginated, the |
Responses
Response Schema: application/json
required | Array of objects (Workspace File) |
required | Array of objects (links_pagination) Links related to this list of resources, for example links for pagination or alternative formats such as a human-readable HTML version. The links array MUST NOT be paginated. If pagination is implemented, the following
For additional relation types see also the lists of common relation types in openEO. |
Response samples
- 200
- 4XX
- 5XX
{- "files": [
- {
- "path": "test.txt",
- "size": 182,
- "modified": "2015-10-20T17:22:10Z"
}, - {
- "path": "test.tif",
- "size": 183142,
- "modified": "2017-01-01T09:36:18Z"
}, - {
- "path": "Sentinel2/S2A_MSIL1C_20170819T082011_N0205_R121_T34KGD_20170819T084427.zip",
- "size": 4183353142,
- "modified": "2018-01-03T10:55:29Z"
}
], - "links": [ ]
}Download a file from the workspace
Offers a file from the user workspace for download. The file is identified by its path relative to the user's root directory.
If a folder is specified as path a FileOperationUnsupported error MUST be sent as response.
Authorizations:
path Parameters
| path required | string Examples:
Path of the file, relative to the user's root directory. MAY include folders, but MUST not include relative references such as Folder and file names in the path MUST be url-encoded. The path separator The URL-encoding may be shown incorrectly in rendered versions due to OpenAPI 3 not supporting path parameters which contain slashes. This may also lead to OpenAPI validators not validating paths containing folders correctly. |
Responses
Response Schema: application/octet-stream
Response samples
- 4XX
- 5XX
{- "id": "550e8400-e29b-11d4-a716-446655440000",
- "code": "SampleError",
- "message": "Parameter 'sample' is missing.",
}Upload a file to the workspace
Uploads a new file to the given path or updates an existing file if a file at the path exists.
Folders are created once required by a file upload. Empty folders can not be created.
Authorizations:
path Parameters
| path required | string Examples:
Path of the file, relative to the user's root directory. MAY include folders, but MUST not include relative references such as Folder and file names in the path MUST be url-encoded. The path separator The URL-encoding may be shown incorrectly in rendered versions due to OpenAPI 3 not supporting path parameters which contain slashes. This may also lead to OpenAPI validators not validating paths containing folders correctly. |
Request Body schema: application/octet-streamrequired
Responses
Response Schema: application/json
| path required | string^[^/\r\n\t\\:'"][^\r\n\t\\:'"]*$ Path of the file, relative to the root directory of the user's server-side workspace.
MUST NOT start with a slash The Windows-style path name component separator Note: The pattern only specifies a minimal subset of invalid characters. The back-ends MAY enforce additional restrictions depending on their OS/environment. |
| size | integer File size in bytes. |
| modified | string <date-time> Date and time the file has lastly been modified, formatted as a RFC 3339 date-time. |
Response samples
- 200
- 4XX
- 5XX
{- "path": "folder/file.txt",
- "size": 1024,
- "modified": "2018-01-03T10:55:29Z"
}Delete a file from the workspace
Deletes an existing user-uploaded file specified by its path. Resulting empty folders MUST be deleted automatically.
Back-ends MAY support deleting folders including its files and sub-folders. If not supported by the back-end a FileOperationUnsupported error MUST be sent as response.
Authorizations:
path Parameters
| path required | string Examples:
Path of the file, relative to the user's root directory. MAY include folders, but MUST not include relative references such as Folder and file names in the path MUST be url-encoded. The path separator The URL-encoding may be shown incorrectly in rendered versions due to OpenAPI 3 not supporting path parameters which contain slashes. This may also lead to OpenAPI validators not validating paths containing folders correctly. |
Responses
Response samples
- 4XX
- 5XX
{- "id": "550e8400-e29b-11d4-a716-446655440000",
- "code": "SampleError",
- "message": "Parameter 'sample' is missing.",
}